67,513
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享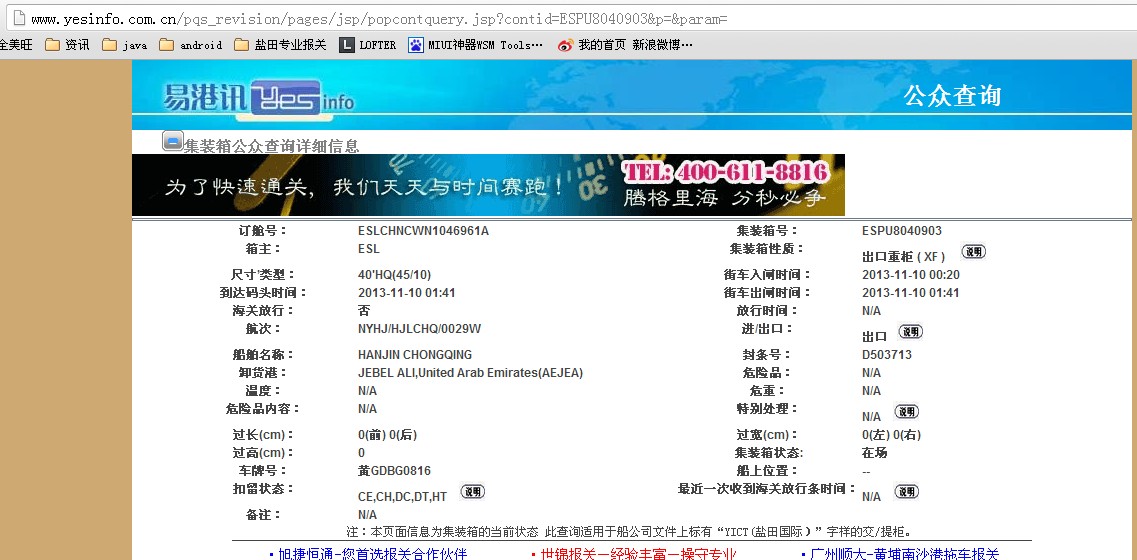

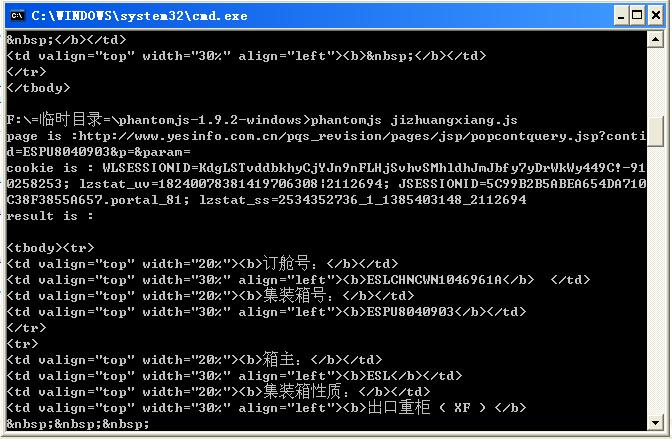
phantom.outputEncoding="gb2312";
var page = require('webpage').create();
page.viewportSize = { width: 1024, height: 768 };
page.settings.userAgent = 'Mozilla/5.0 (Windows NT 5.2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.72 Safari/537.36'; //chrome
page.settings.loadImages = true;
page.settings.javascriptEnabled = true;
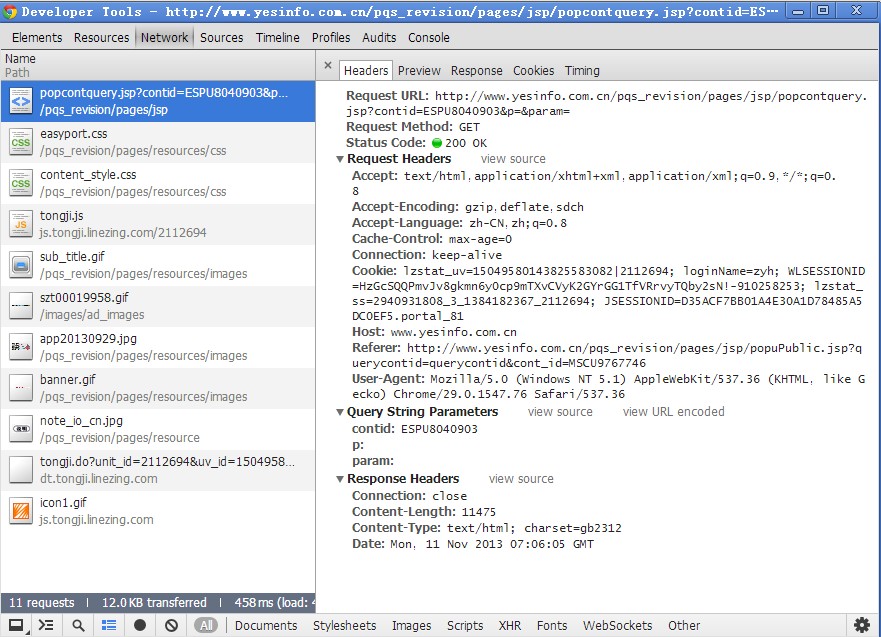
page.open("http://www.yesinfo.com.cn/pqs_revision/pages/jsp/popuPublic.jsp", function(status) {
page.onUrlChanged = function(url) { //当地址变化
console.log("page url :"+url);
};
if (status !== 'success') {
console.log('FAIL to load the address');
phantom.exit();
} else {
window.setTimeout(function () {
page.evaluate(function () {
document.querySelector('input[name=cont_id]').value = 'ESPU8040903';
document.querySelector('input[name=Submit12]').click();
});
}, 2000);
window.setTimeout(function () {
var cookie=page.evaluate(function () {
return document.cookie;
});
var result=page.evaluate(function () {
return document.querySelector('.sub_title ~ table').innerHTML;
});
console.log("cookie : "+cookie);
console.log("result : "+result);
phantom.exit();
}, 5000);
}
});