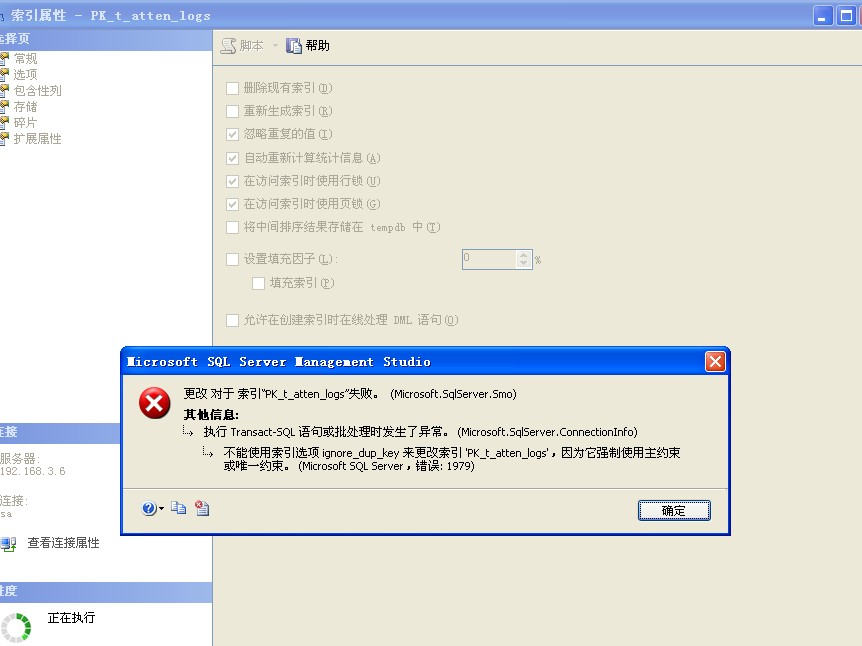
解释:
Specifies the error response when an insert operation attempts to insert duplicate key values into a unique index. The IGNORE_DUP_KEY option applies only to insert operations after the index is created or rebuilt. The option has no effect when executing CREATE INDEX, ALTER INDEX, or UPDATE. The default is OFF.
如果要更新已有的记录,很麻烦(或者说效率很低),我以前用类似的方法做过,我用INSERT INTO ... VALUE ...一条一条插入, 检错时如果发现是重复主键错误,则先删除这条记录, 再resume, 即重新插入.
慢就慢在删除时又整个表找了一遍,我试了四千条重复的插入,用insert into ... select到一个新表,只要几秒钟,而用先删除重复再插入的方法, 时间约用了1分钟!
--比如
insert into test
select '123456',getdate(),'01'
from test t1
where not exists(select 1 from test t2 where t2.xh='123456' and t2.worktime=getdate())


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享