前几天一个一同学在QQ上问
--tableTest表,ID上建立了聚集索引
select * from tableTest where id in (1,9999,12345);
类似这样一个查询,id上有聚集索引,
应该是受到IN的查询方式用不到索引的影响,不太敢用,但试着用in的方式去执行,也不见得慢,
因为没有理论证明,所以感觉不放心,
说是全部放到in里面一次性查出来块还是一个一个地查快
所以在讨论这个问题
我首先看了IO,比如三个ID,
一个一个查,逻辑IO是3(3次就是9了),
放到in 里面一次性查询出来,逻辑IO是9
从这一点上说,IO是一样的,不存在in的方式用不到索引的问题
比一个一个查询,最起码节省了数据库连接的开销
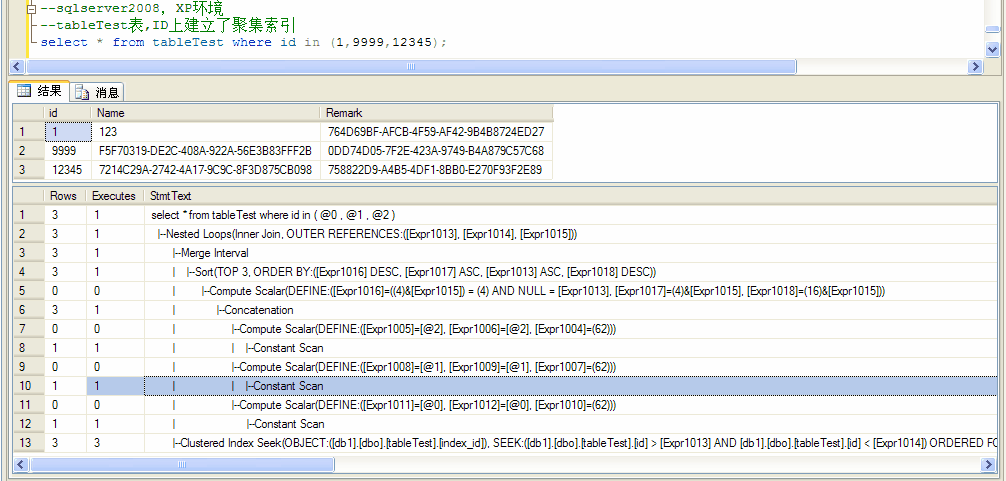
后来我在本机sqlserver2008看了一下执行计划,就有点犯晕了,
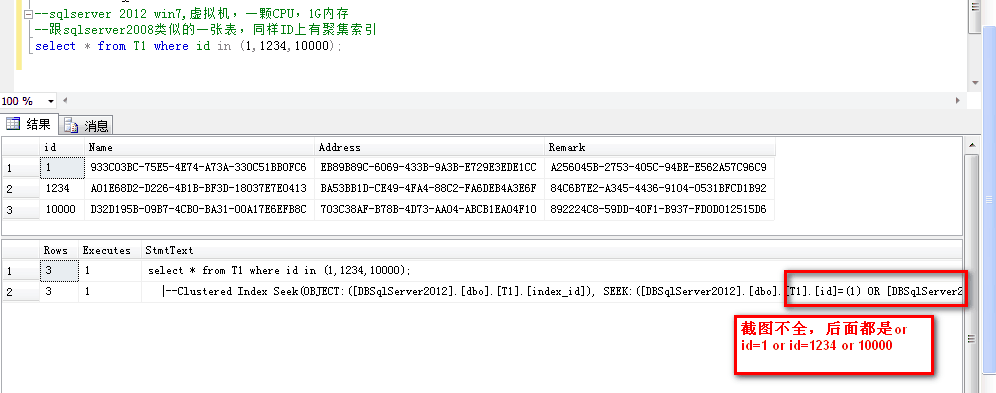
同样放到sqlserver2012下,执行计划又是不太一样的,直接上图吧
主要是搞不懂sqlserver2008下面的这个执行计划
还请大家指教
.



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享






