

27,579
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

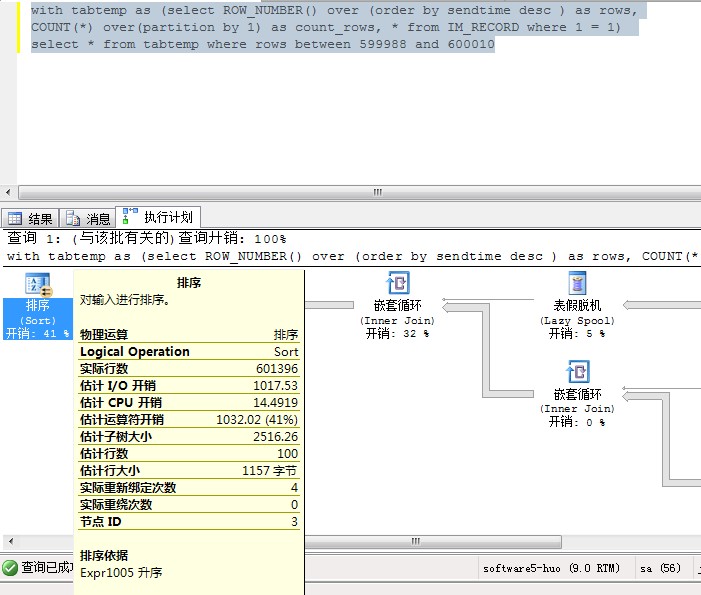

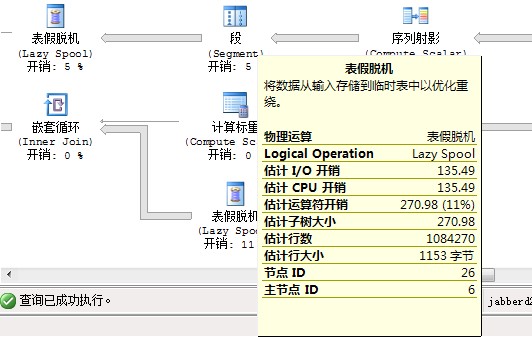
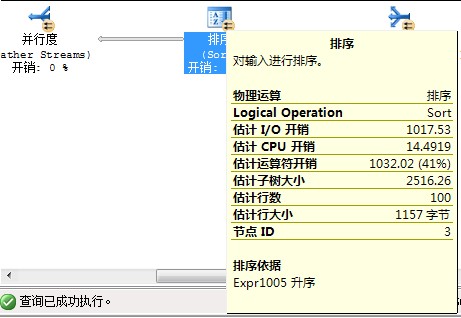
 你这是预估执行计划还是实际执行计划?
你这是预估执行计划还是实际执行计划?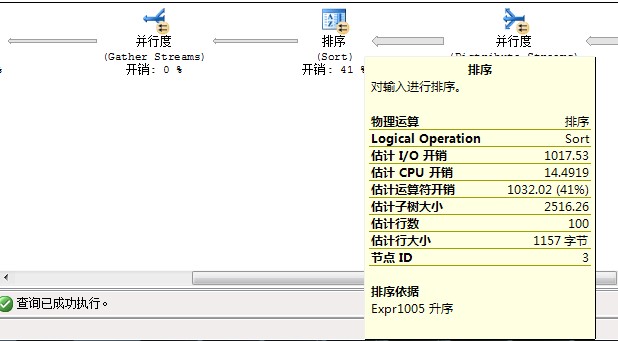
;with tabtemp as
(
select ROW_NUMBER() over (order by time desc) as rows,
(select COUNT(*)
from from mytable
where time > '2013-10-10 00:00:00'
and description like '%描述%') as count_rows, --记录条数
*
from mytable
where time > '2013-10-10 00:00:00' and description like '%描述%'
)
select * from tabtemp
where rows between 220000 and 230000 ;;with tabtemp as
(
select ROW_NUMBER() over (order by time desc) as rows,
(select COUNT(*)
from from mytable
where time > '2013-10-10 00:00:00'
and description like '%描述%') as count_rows, --记录条数
*
from mytable
where time > '2013-10-10 00:00:00' and description like '%描述%'
)
select * from tabtemp
where rows between 220000 and 230000 ;;with tabtemp as
(
select ROW_NUMBER() over (order by time desc) as rows,
(select COUNT(*)
from from mytable
where time > '2013-10-10 00:00:00'
and description like '%描述%') as count_rows, --记录条数
*
from mytable
where time > '2013-10-10 00:00:00' and description like '%描述%'
)
select * from tabtemp
where rows between 220000 and 230000 ;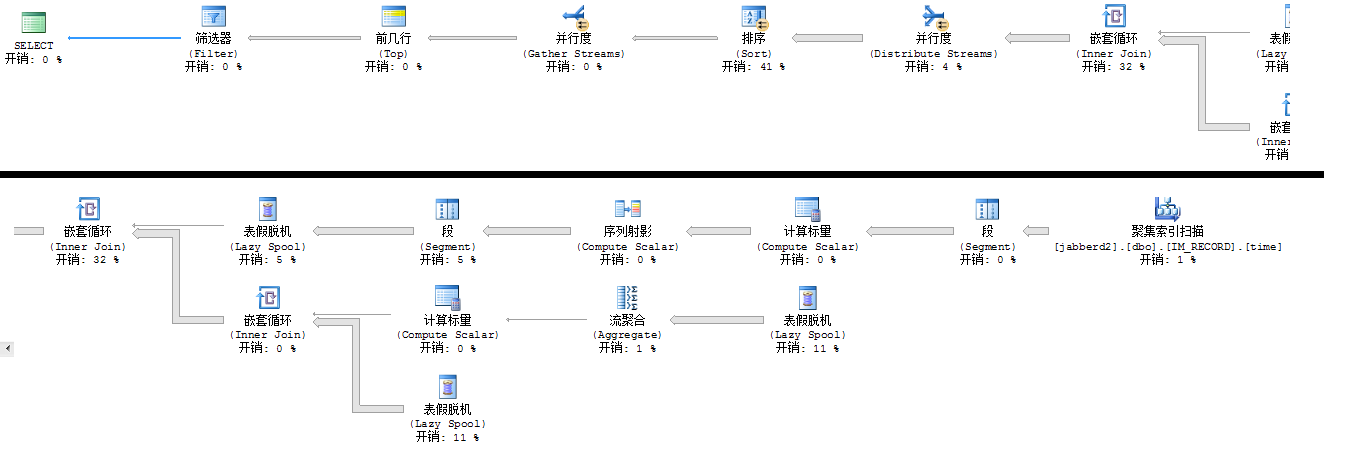
;with tabtemp as
(
select ROW_NUMBER() over (order by time desc) as rows,
COUNT(*) over(partition by 1) as count_rows, --记录条数
*
from mytable
where time > '2013-10-10 00:00:00' and description like '%描述%'
)
select * from tabtemp
where rows between 220000 and 230000 ;;with tabtemp as
(
select ROW_NUMBER() over (order by time desc) as rows,
COUNT(*) over(partition by 1) as count_rows, --记录条数
*
from mytable
where time > '2013-10-10 00:00:00' and description like '%描述%'
)
select * from tabtemp
where rows between 220000 and 230000 ;
