案例1:
大多数情况下,想从AWR报告中判断数据库性能正不正常,不是一份孤立的AWR报告所能支撑的,需要有多份AWR作为分析依据,特别是需要指定作为基线的AWR报告。基线描述了正常性能状态下的各个指标,通过和基线指标作比较,可以找出哪些指标变差了,然后通过指标的关联性分析,初步诊断出可能的原因。
1、基线报告中的指标:
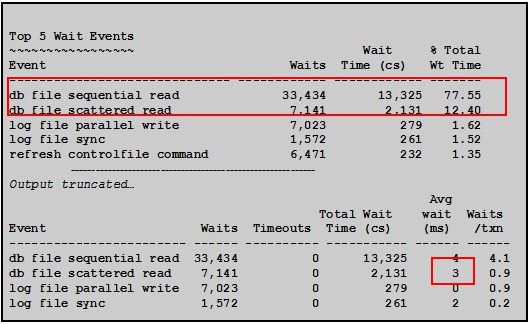
可以看出2个主要的物理读等待事件指标为:
db file sequential read:平均每次4ms
db file scattered read:平均每次3ms
2、待分析报告中的指标:
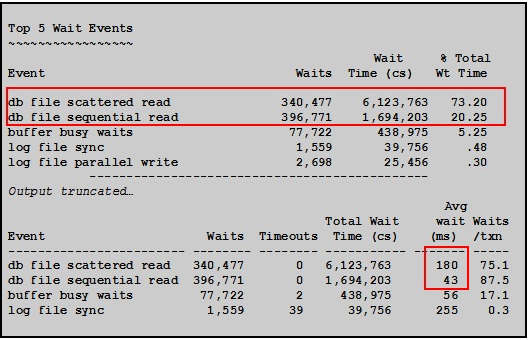
db file sequential read:平均每次43ms
db file scattered read:平均每次180ms
以上物理读指标比基线高了很多倍,特别是全表读指标(db file scattered read),更是明显。
3、待分析报告中和物理读相关的指标:
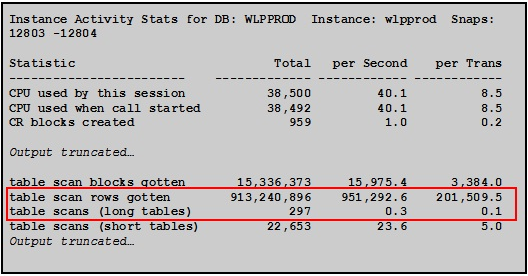
table scan rows gotten:951,292.6/s
table scans (long tables):0.3/s
这些反映全表扫描的指标都比基线报告中的对应指标高了很多。
进一步,分析各个表空间的物理读情况:
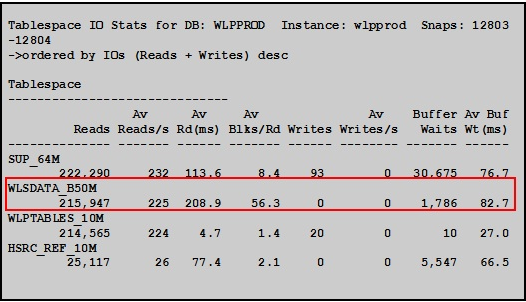
WLSDATA_B50M表空间每次读56.3块,很明显是在做全表扫描。
4、结论:
在待分析AWR报告对应的采样时间段期间,数据库负载中出现了比平时多得多的全表扫描活动,这些活动主要集中在WLSDATA_B50M表空间,导致物理读等待时间显著增加,数据库性能变差。
案例2:
在负载基本相同的情况下,一些指标出现了不正常的现象。
1、关键指标:主要等待事件

buffer busy waits、enqueue、db file parallel write、write complete waits等待事件的平均等待时间很大,不正常。
2、相关指标
活动统计:找出和db file parallel write、write complete waits等待事件相关并且不正常的活动统计指标
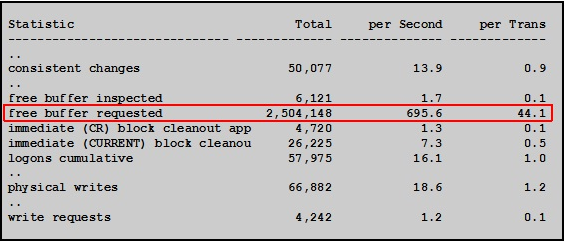
free buffer requested指标明显偏大,和db writer进程写脏快的速度太慢有关。
表空间及数据文件物理读写统计:找出buffer busy waits在表空间及数据文件的分布情况(以下只列出了表空间的分布情况)
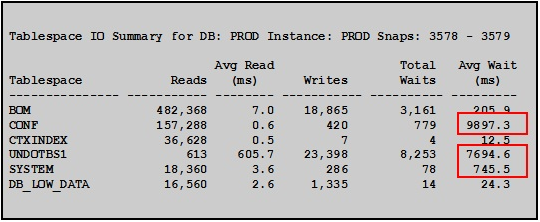
CONF、UNDOTBS1、SYSTEM的平均等待时间明显偏大。
Enqueue活动统计:找出各个Enqueue类型的活动及等待情况
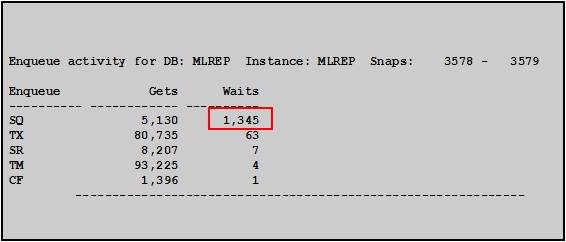
SQ类型的enqueue争用偏多,应该和SYSTEM表空间的等待有关。
3、结论:
某些表空间下的数据文件的等待时间明显变长,导致数据库的整体响应时间变慢。至于为什么这些数据文件的读写会变慢,需要进一步从操作系统和存储方面去诊断。
目前这些数据都存放在数据库中(mysql,跟orcale无关 只是分析orcale的相关的指标而已)如下图
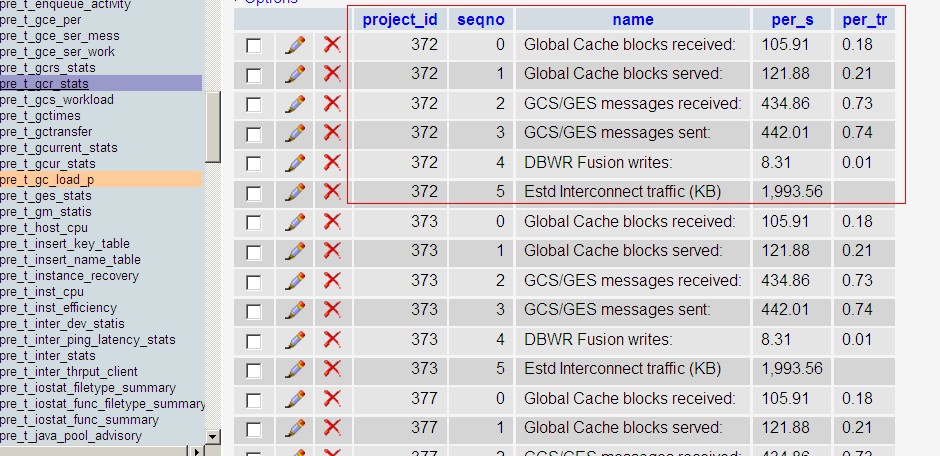
红色框里说明是一个报告里的所有表的指标值
将一个报告设置成基线报告 其他报告和这个基线报告对比 如果指标值差很大 就需要进一步的分析 并得出相应的结论(上述表大概有200个)
求思路 有点繁琐




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

