65,208
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享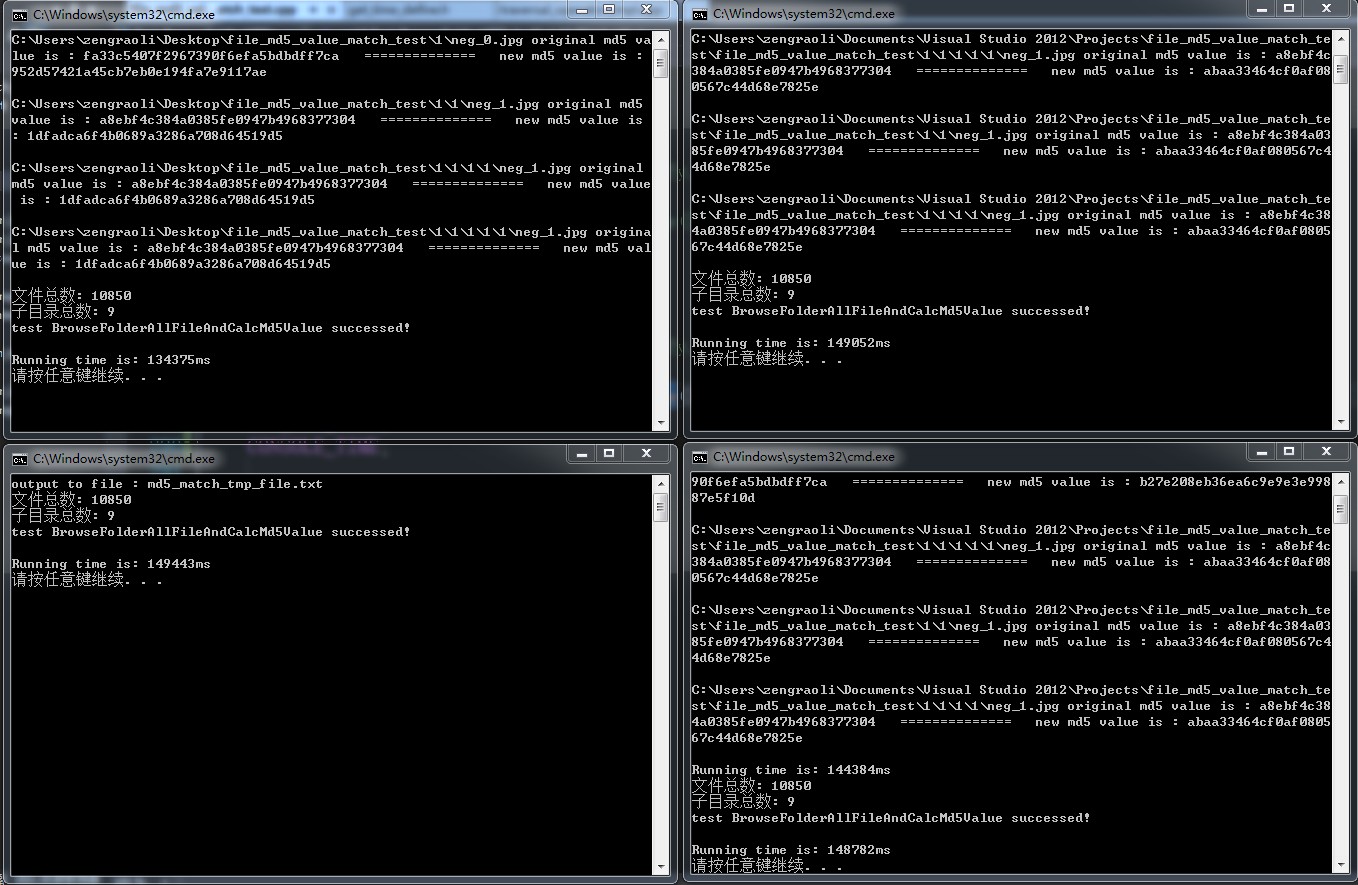
void TraversalOperator_impl::Md5Match()
{
// 先从md5_match_tmp_file.txt文件中获取到临时的md5值,存放到current_hash_info_中
GetAllFileMd5ValueFromFile(current_hash_info_, MD5_MATCH_TMP_FILE);
// 再去和file_hash_info_中的数据进行比较
hash_map<string, string>::iterator it_file_hash_info_;
hash_map<string, string>::iterator it_current_hash_info_;
for (it_current_hash_info_ = current_hash_info_.begin(); it_current_hash_info_ != current_hash_info_.end(); it_current_hash_info_++)
{
for (it_file_hash_info_ = file_hash_info_.begin(); it_file_hash_info_ != file_hash_info_.end(); it_file_hash_info_++)
{
// 找到key
if (!it_file_hash_info_->first.compare(it_current_hash_info_->first))
{
// 匹配value
if (!it_file_hash_info_->second.compare(it_current_hash_info_->second))
{
break;
}
else
{
cout << it_current_hash_info_->first << " original md5 value is : " << it_file_hash_info_->second;
cout << " ============== new md5 value is : " << it_current_hash_info_->second << endl;
cout << endl;
}
break;
}
}
}
}

#include "stdafx.h"
#include "iostream"
#include "fstream"
#include "string"
#include "sstream"
using namespace std;
#include "unordered_map"
#include "time.h"
#define BEGINE_GET_TIME clock_t start_time = clock();
#define ENG_GET_TIME clock_t end_time = clock();
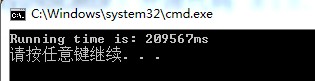
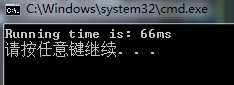
#define CONSOLE_TIME cout << "Running time is: " << static_cast<double>(end_time - start_time) / CLOCKS_PER_SEC * 1000 << "ms" << endl; //输出运行时间
int _tmain(int argc, _TCHAR* argv[])
{
unordered_map<string, string> test;
stringstream ss;
string tmp_key;
string tmp_value;
for (int index = 0; index < 10001; index++)
{
ss << "zeng"; ss << index;
ss >> tmp_key;
ss.clear();
ss << "zengraoli"; ss << index;
ss >> tmp_value;
ss.clear();
test.insert(pair<string, string>(tmp_key, tmp_value));
ss.str("");
}
// BEGINE_GET_TIME;
// // 先来看看遍历的速度
// for (int count = 0; count < 10000; count++)
// {
// unordered_map<string, string>::iterator it;
// for (it = test.begin(); it != test.end(); it++)
// {
// if (it->first == "zeng10000")
// {
// if (it->second == "zengraoli10000")
// {
// // cout << "find" << endl;
// }
// }
// }
// }
// ENG_GET_TIME;
// CONSOLE_TIME;
BEGINE_GET_TIME;
// 先来看看遍历的速度
for (int count = 0; count < 10000; count++)
{
unordered_map<string, string>::iterator it;
it = test.find("zeng10000");
if (it == test.end())
{
cout << "not find" << endl;
}
else
{
if (it->second == "zengraoli10000")
{
// cout << "find" << endl;
}
}
}
ENG_GET_TIME;
CONSOLE_TIME;
return 0;
}