

22,296
社区成员
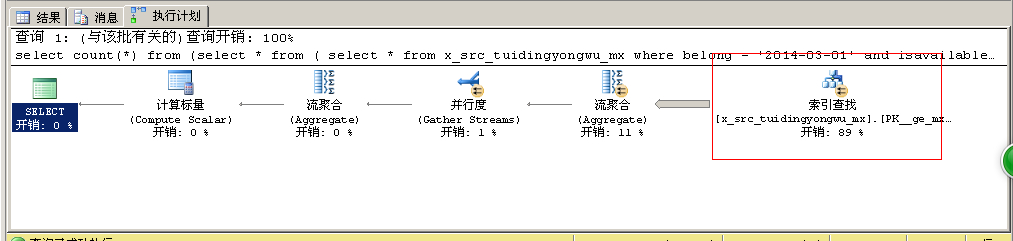
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
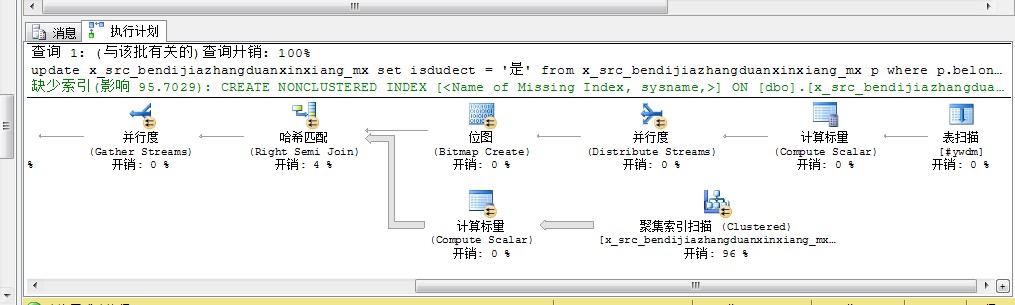
分享update x_src_bendijiazhangduanxinxiang_mx
set isdudect = '是'
from x_src_bendijiazhangduanxinxiang_mx p
where p.belong = '20140101' and p.isavailable = 1
and p.kt_time_bak is not null
and p.number in(
select parent_number from #ywdm
where convert(varchar(7),DATEADD(mm, DATEDIFF(mm,0,td_time), 0),120 ) > convert(varchar(7),DATEADD(mm, DATEDIFF(mm,0,dateadd(month,-6,p.kt_time_bak)), 0),120)
and convert(datetime,td_time,120 ) < convert(datetime,p.kt_time_bak ,120))




BEGIN TRAN
UPDATE x_src_bendijiazhangduanxinxiang_mx
SET isdudect = '是'
FROM x_src_bendijiazhangduanxinxiang_mx p
WHERE p.belong = '20140101'
AND p.isavailable = 1
AND p.kt_time_bak IS NOT NULL
AND p.number IN (
SELECT parent_number
FROM #ywdm
WHERE CONVERT(VARCHAR(7), DATEADD(mm, DATEDIFF(mm, 0, td_time), 0), 120) > CONVERT(VARCHAR(7), DATEADD(mm,
DATEDIFF(mm, 0,
DATEADD(month,
-6,
p.kt_time_bak)),
0), 120)
AND CONVERT(DATETIME, td_time, 120) < CONVERT(DATETIME, p.kt_time_bak, 120) )
ROLLBACK
