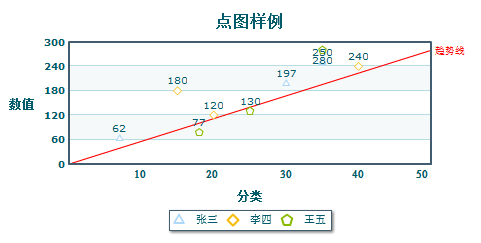
我现在要做一个点状图的趋势线,网上找了一些算法,发现得这么实现
--------------------思路-----------------------
建立线性趋势线,对于趋势方程y=ax+b. a,b取什么才是最能代表那一组数据的?
这个问题,一般我们这样认为:
存在这样的a,b,使得所有的数据点(xi,yi)到这条直线(y=ax+b)的距离和D为最小
--------------------^^^^^-----------------------
所以我要的结果是根据一组坐标获得y=ax+b的过程,大家如果尝试解答可以使用(1,12)(2,27)(3,83)(4,39)(5,48)(6,32)这样一组坐标,我在维基上找了另外一些资料:
》》》》》》》》》》》》》资料》》》》》》》》》》》
http://http://zh.wikipedia.org/wiki/%E6%9C%80%E5%B0%8F%E4%BA%8C%E4%B9%98%E6%B3%95

结贴后我会贴出具体实现代码,求大神回复,谢谢




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



