多谢~~啊!我们库里的基础宽表都是建立在sys用户下的。有一点没搞懂的是,我之前做这样的连接操作是不需要耗时很长的,现在搞不懂怎么连接20w的数据都要20多分钟,是因为数据库的什么设置被改了吗? ps:重新采集两张表的统计信息?这个怎么做。求指导
17,377
社区成员
95,112
社区内容
加载中
试试用AI创作助手写篇文章吧


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享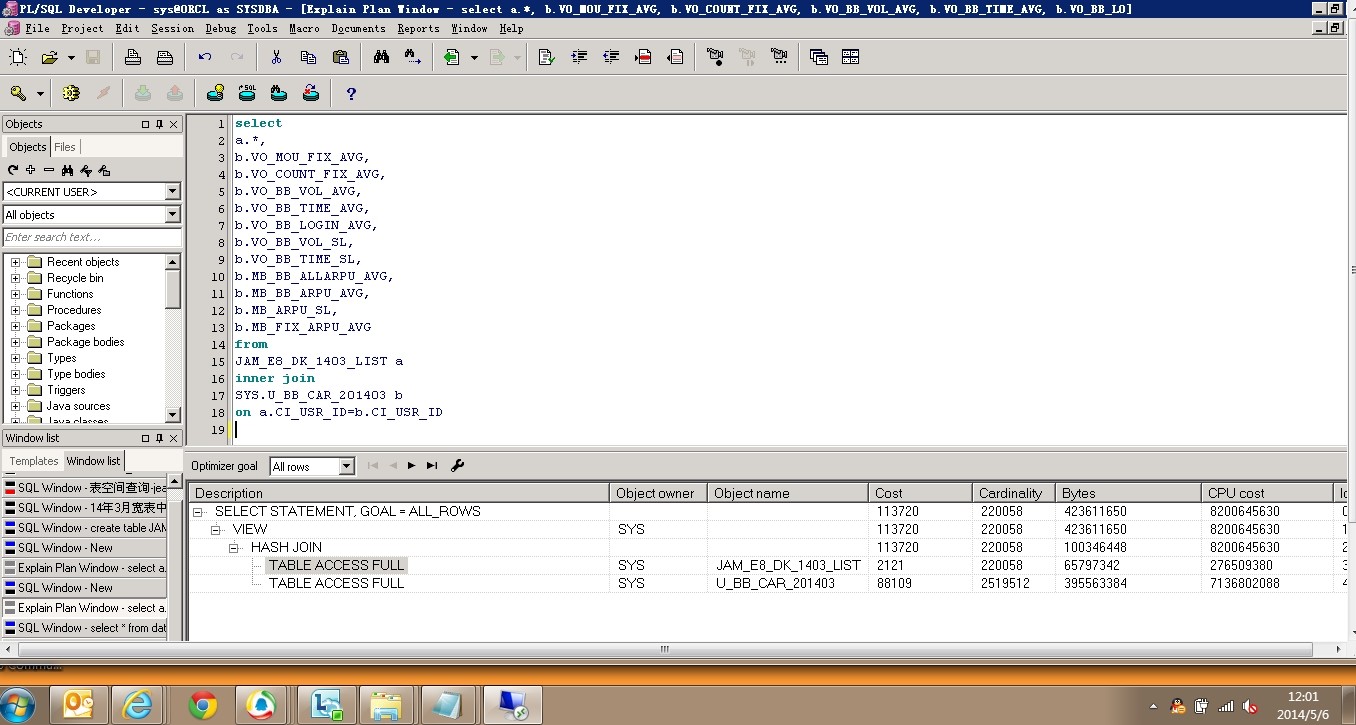
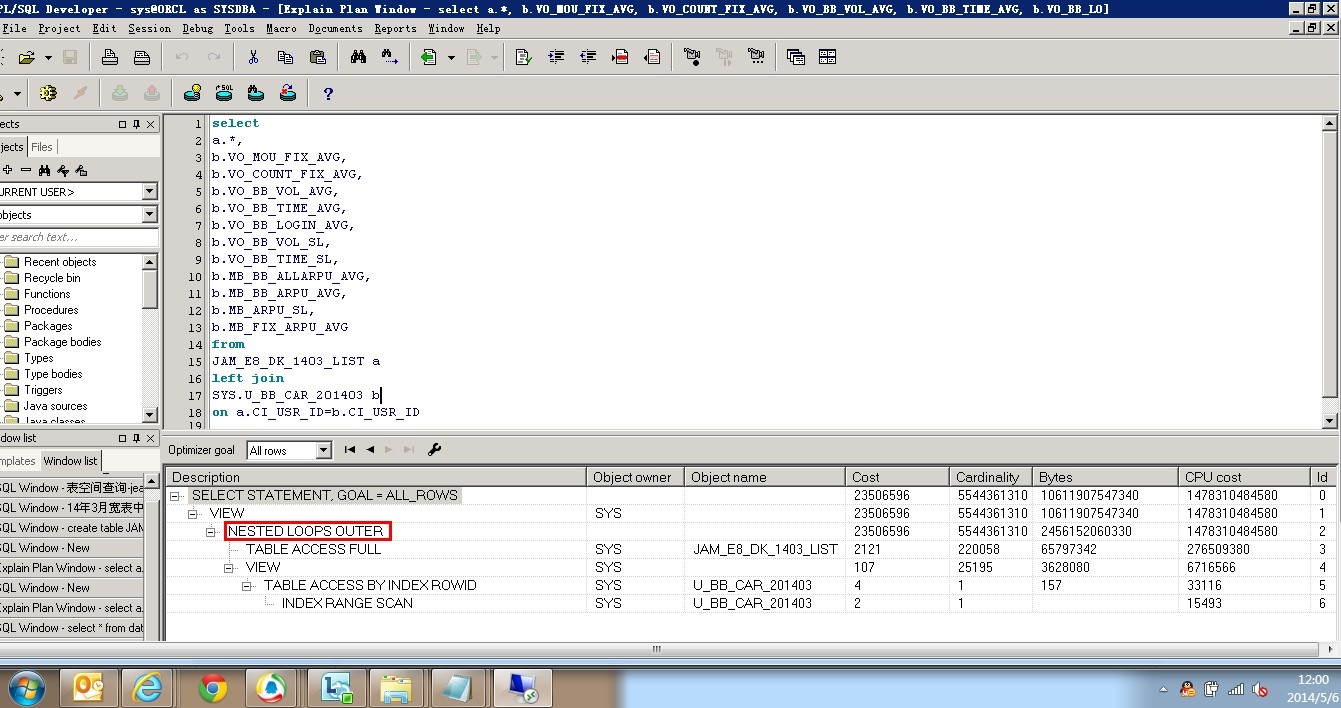



 两种连接适用于不同的场景.....
两种连接适用于不同的场景..... 
