


34,576
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享







SELECT OBJECT_NAME(i.[object_id]) AS [Table Name] ,
i.name
FROM sys.indexes AS i
INNER JOIN sys.objects AS o ON i.[object_id] = o.[object_id]
WHERE i.index_id NOT IN ( SELECT ddius.index_id
FROM sys.dm_db_index_usage_stats AS ddius
WHERE ddius.[object_id] = i.[object_id]
AND i.index_id = ddius.index_id
AND database_id = DB_ID() )
AND o.[type] = 'U'
ORDER BY OBJECT_NAME(i.[object_id]) ASC;
SELECT OBJECT_NAME(ddius.[object_id]) AS [Table Name] ,
i.name AS [Index Name] ,
i.index_id ,
user_updates AS [Total Writes] ,
user_seeks + user_scans + user_lookups AS [Total Reads] ,
user_updates - ( user_seeks + user_scans + user_lookups ) AS [Difference]
FROM sys.dm_db_index_usage_stats AS ddius WITH ( NOLOCK )
INNER JOIN sys.indexes AS i WITH ( NOLOCK ) ON ddius.[object_id] = i.[object_id]
AND i.index_id = ddius.index_id
WHERE OBJECTPROPERTY(ddius.[object_id], 'IsUserTable') = 1
AND ddius.database_id = DB_ID()
AND user_updates > ( user_seeks + user_scans + user_lookups )
AND i.index_id > 1
ORDER BY [Difference] DESC ,
[Total Writes] DESC ,
[Total Reads] ASC;
SELECT user_seeks * avg_total_user_cost * ( avg_user_impact * 0.01 ) AS [index_advantage] ,
dbmigs.last_user_seek ,
dbmid.[statement] AS [Database.Schema.Table] ,
dbmid.equality_columns ,
dbmid.inequality_columns ,
dbmid.included_columns ,
dbmigs.unique_compiles ,
dbmigs.user_seeks ,
dbmigs.avg_total_user_cost ,
dbmigs.avg_user_impact
FROM sys.dm_db_missing_index_group_stats AS dbmigs WITH ( NOLOCK )
INNER JOIN sys.dm_db_missing_index_groups AS dbmig WITH ( NOLOCK ) ON dbmigs.group_handle = dbmig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS dbmid WITH ( NOLOCK ) ON dbmig.index_handle = dbmid.index_handle
WHERE dbmid.[database_id] = DB_ID()
ORDER BY index_advantage DESC;
SELECT '[' + DB_NAME() + '].[' + OBJECT_SCHEMA_NAME(ddips.[object_id],
DB_ID()) + '].['
+ OBJECT_NAME(ddips.[object_id], DB_ID()) + ']' AS [statement] ,
i.[name] AS [index_name] ,
ddips.[index_type_desc] ,
ddips.[partition_number] ,
ddips.[alloc_unit_type_desc] ,
ddips.[index_depth] ,
ddips.[index_level] ,
CAST(ddips.[avg_fragmentation_in_percent] AS SMALLINT) AS [avg_frag_%] ,
CAST(ddips.[avg_fragment_size_in_pages] AS SMALLINT) AS [avg_frag_size_in_pages] ,
ddips.[fragment_count] ,
ddips.[page_count]
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'limited') ddips
INNER JOIN sys.[indexes] i ON ddips.[object_id] = i.[object_id]
AND ddips.[index_id] = i.[index_id]
WHERE ddips.[avg_fragmentation_in_percent] > 15
AND ddips.[page_count] > 500
ORDER BY ddips.[avg_fragmentation_in_percent] ,
OBJECT_NAME(ddips.[object_id], DB_ID()) ,
i.[name]
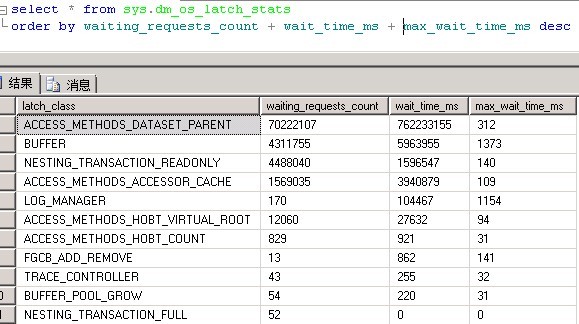
select * from sys.dm_os_latch_stats 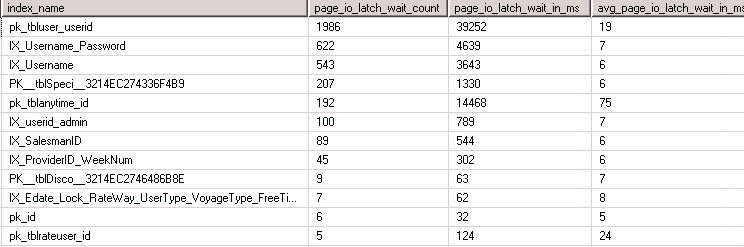



SELECT '[' + DB_NAME() + '].[' + OBJECT_SCHEMA_NAME(ddios.[object_id])
+ '].[' + OBJECT_NAME(ddios.[object_id]) + ']' AS [object_name] ,
i.[name] AS index_name ,
ddios.page_io_latch_wait_count ,
ddios.page_io_latch_wait_in_ms ,
( ddios.page_io_latch_wait_in_ms / ddios.page_io_latch_wait_count ) AS avg_page_io_latch_wait_in_ms
FROM sys.dm_db_index_operational_stats(DB_ID(), NULL, NULL, NULL) ddios
INNER JOIN sys.indexes i ON ddios.[object_id] = i.[object_id]
AND i.index_id = ddios.index_id
WHERE ddios.page_io_latch_wait_count > 0
AND OBJECTPROPERTY(i.object_id, 'IsUserTable') = 1
ORDER BY ddios.page_io_latch_wait_count DESC ,
avg_page_io_latch_wait_in_ms DESC


