Netflix公司拥有海量的视频、图片数据,公司不断创新技术提升用户使用体验,最新消息显示Netflix承认正在开发新的技术开展人工智能领域的应用,该公司广泛采用高级人工智能技术,尤其以深度学习技术被大家所熟知。着眼深度学习可以让Netflix的电影推荐更准确,但是深度学习领域还有很多技术难题未被解决,Netflix技术博客网站的Alex chen等人结合自身实践,分享了在AWS上实现分布式人工智能网络的经验。
以下为译文:
在以前的博客中提到,Netflix一直不断创新,努力通过寻找更好的方法为我们的会员找到最好的电影和电视节目。当一个新的算法技术例如深度学习在其他领域(如图像识别、神经成像、语言模型和语音识别)展现非常好的前景时,我们没有惊喜,而是试图找出如何应用这些技术来改善我们的产品。在这篇文章中,我们将和大家分享在Netflix实验这些方法过程中建立基础设施的一些经验。希望对从事类似算法的人有所帮助,尤其是那些也使用AWS基础设施的人们。然而,我们不会详细说明我们如何使用人工神经元网络的变量实现个性化,因为它现在还在研究阶段。
许多研究人员指出,大部分流行的深度学习算法技术已经为大家熟知和了解。最近这一领域的革新已经能让这些技术能够实际应用,包括设计和实现的架构,可以在合理的资源和时间的情况下执行这些技术。第一个大规模深度学习成功实例是连续几天使用1000台机器的16000个CPU内核训练一个神经网络。尽管这具有里程碑意义,但是所需的基础设施、成本、计算时间仍然是不实际的。
Andrew Ng和他的团队解决了这个问题。他们使用强大而廉价的GPU代替大型集群的CPU,使用此体系结构仅用3台机器在几天内就训练出比原来大6.5倍的模型。在另一项研究中,Schwenk等人表明,在GPU上训练这些模型可以大大提高性能,即使和高端的多核CPU相比。
考虑到我们在云计算领域的技术和领导能力,我们利用GPU和AWS的优势,实现大规模神经网络训练系统。我们想要使用合理数量的机器,利用神经网络方法实现强大的机器学习解决方案。我们还需要避免在一个专用的数据中心里使用特殊的机器,按需计算的能力可以在AWS上获得。
分布式机器学习的层次
你们中的一些人可能会认为上面描述的场景不是传统意义上的分布式机器学习。例如,在上面所提到Ng等人,他们将学习算法本身分配在不同的机器上。虽然这种方法在某些情况下可能有意义,但是我们发现它们并不是很规范,特别是当一个数据集可以存储在单一实例上。要理解为什么,我们首先需要解释可分布式模型的不同层次。
在标准情况下,我们会有一个特定的模型与多个实例。这些实例在你的问题空间可能对应于不同的分区。典型的情况是不同国家或地区要有不同的模型训练,因为分布特征甚至主题空间各个国家和地区都是不同的。这代表第一个初始级别,在这里我们可以决定分配学习过程。我们可以,例如,Netflix在41个国家运营,我们可以在每个国家都进行独立的机器训练,因为每个地区的训练可以完全独立。
然而,正如上面所解释的,培训单一实例实际上意味着训练和测试数个模型,每个对应一个不同的hyperparameters组合。这是第二个层次,过程可以被分配。这个级别是特别有趣的,如果有许多参数优化和一个好的策略优化它们,如贝叶斯优化与高斯过程。运行之间唯一的的通信是hyperparameter设置和测试评价指标。
最后,该算法训练本身可以是分布式的。这也是有趣的,但它是有代价的。例如,培训ANN是一个比较集中通信的过程。考虑到你可能会有成千上万的核心在一个GPU实例上,如果你能充分利用GPU,避免进入昂贵的跨机器通信场景,这将是很方便的。因为在一台机器上使用内存通信通常远远快于通过网络。
下面下面的伪代码演示了这三个层次:

在本文里,我们将阐述在我们的用例中如何解决级别1和2分布。请注意,我们不需要解决3层分布的原因之一是因为我们的模型有数百万的参数。
优化CUDA Kernel
我们处理分布问题之前,必须确保基于GPU的并行训练是有效的。我们首先在自己开发的机器上进行概念验证,然后再来处理如何扩展机器问题。我们开始使用Nvidia Quadro 600 GPU的联想S20工作站。这个GPU 有98内核,并且为我们的实验提供了一个有用的基准,特别是考虑到我们打算在AWS上使用一个更强大的机器。我们第一次尝试训练神经网络模型花了7个小时。
然后我们在EC2的cg1.4xlarge实例中运行相同的代码来训练该模型,它有一个更强大的448内核的Tesla M2050 。然而,训练时间从7小时上升到20小时以上。分析表明,大部分时间是花在Nvidia性能原始库函数调用,例如nppsMulC_32f_I、nppsExp_32f_I。cg1实例比联想S20重复调用npps函数多花费了十几倍的系统时间。
当我们试图找出问题的根源,我们使用定制的cuda kernel重新实现npps函数,例如将nppsMulC_32f_I函数替换为:

用这种方法取代所有npps函数这样的神经网络代码使cg1实例上的总培训时间从20多小时减少到47分钟。训练100万样本用去96秒GPU的时间。使用相同的方法在联想S20总训练时间也从7小时减少到2小时。
PCI 配置空间和虚拟环境
当我们处理这个问题时,我们也曾与AWS团队找到一个好的解决方案,不需要内核补丁。在这样做的时候,我们发现,相关性能下降与NVreg_CheckPCIConfigSpace内核参数有关。从RedHat得知,将这个参数设置为0,将会让访问PCI配置空间非常缓慢。在虚拟环境中,如AWS,这些访问导致hypervisor陷阱,导致更慢的访问。
NVreg_CheckPCIConfigSpace是一个参数,可以设置:
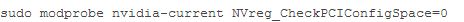
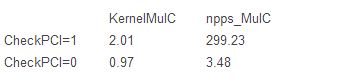
我们使用基准测试这个参数变化的影响,反复调用MulC(128 x1000次)。下面是我们cg1.4xlarge实例运行时间(秒):

如你所见,禁用访问PCI空间在最初的函数调用时有惊人的效果,减少95%运行时间。效果是显著的,甚至在我们优化内核函数时,运行时间也节省近25%。然而,重要的是,即使PCI访问是禁用的,我们的定制函数性能比默认的也提升60%。
我们还应该指出,还有其他方法,我们到目前为止还没有找到,但对其它也是有用的。首先,我们可以将我们的代码优化,通过应用一个内核融合技巧,合并一些计算步骤到一个内核将会减少内存访问。最后,我们可以考虑使用Theano,GPU匹配Python编译器,也应该可以在这些情况下提高性能。
G2 实例
虽然我们最初的工作是使用cg1.4xlarge EC2实例,但是我们对新的EC2 GPU g2.2xlarge实例类型同样感兴趣,它具有1536内核 GRID K520 GPU (GK104 chip)。目前我们的应用程序也被GPU内存带宽限制,GRID K520内存带宽是198 GB /秒,相比Tesla M2050的148 GB /秒已经有所改善。当然,使用GPU与更快的内存将会更快(例如TITAN的内存带宽达到288 GB / sec)。
我们用默认的函数和自己的函数在g2.2xlarge实例上重复相同的比较(有或没有PCI空间访问)。
最初令人惊讶的事实是,当启用PCI访问时,我们测出g2实例比cg1性能更差。然而,禁用它,相比cg1实例改进的性能在45%-65%之间。我们KernelMulC定制函数功能要好70%以上,基准时间在1秒内。因此,切换到G2,正确的配置将会使我们的实验更快。
分布式贝叶斯hyperparameter优化
一旦我们优化了单节点训练和测试操作,我们就准备解决hyperparameter优化的问题。如果你不熟悉这个概念,这里可以简单解释为:大多数机器学习算法的参数优化,这通常被称为hyperparameters,以便和学习算法产生的模型参数区分。例如,在神经网络中,我们可以考虑优化隐藏单位、学习速率等。为了优化这些,你需要训练和测试不同的hyperparameters 组合和为你的最终模型选择最佳的。当面对一个复杂的模型,其中每训练一个都有时间消耗,以及有很多hyperparameters调整,执行这些详尽的网格搜索代价非常大。幸运的是,通过考虑参数调整你可以做的比这更好。
解决这种问题的一种方法是使用贝叶斯优化,算法的性能将被高斯过程建模为一个示例。高斯过程对回归分析非常有效,但是他们扩展到大的问题时还是有困难的,当数据有限时。他们运行的很好,就像我们遇到在执行hyperparameter优化一样。我们使用package spearmint 执行贝叶斯优化,为神经网络训练算法找到最好的hyperparameters。我们通过选择一套hyperparameters使spearmint和我们的训练算法关联,然后使用我们GPU优化代码训练神经网络。然后测试这个模型,测试度量结果用于更新hyperparameter。
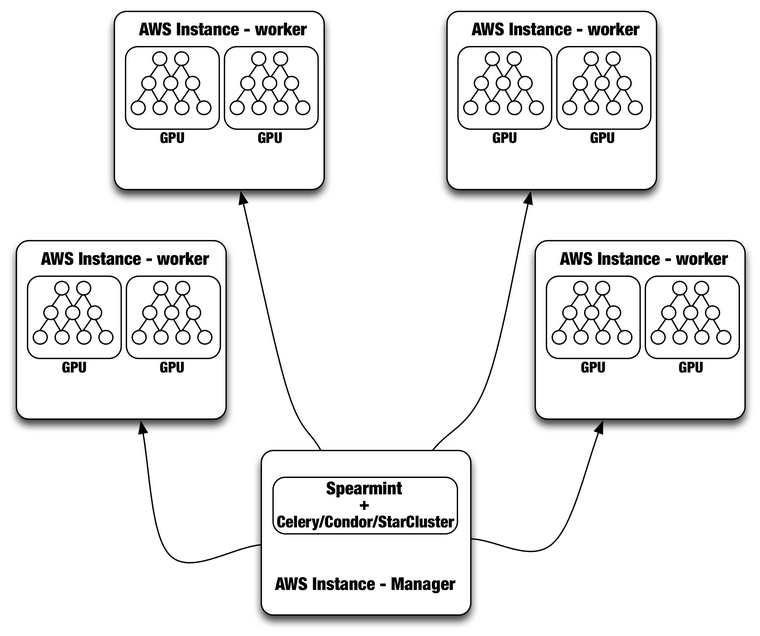
我们从GPU得到高性能,但我们每台机器只有1 - 2 GPU,所以我们想利用AWS的分布式计算能力为所有的配置来执行hyperparameter调优,如每个国际地区用不同的模型。为此,我们使用分布式任务队列Celery 将任务发送到GPU。每个worker process听从任务队列,并且在一个GPU上运行。这将让我们每天可以为所有的国际地区调优,训练,和升级模型。
尽管Spearmint + Celery系统一直在运行,但是我们目前正在评估使用HTCondor或StarCluster更完整和复杂的解决方案。HTCondor可以用来管理任何Directed Acyclic Graph (DAG)工作流。它处理输入/输出文件传输和资源管理。为了使用Condor,我们需要每个计算节点用给定的ClassAd(例如SLOT1_HAS_GPU = TRUE;STARD_ATTRS = HAS_GPU)注册为管理人员。然后用户可以通过配置“需求= HAS_GPU”提交作业,这样的工作只运行在AWS实例上,并且要有一个可用的GPU。使用Condor的主要优势是,它还管理不同模型的训练所需的分布式数据。Condor也允许我们以管理员身份进行Spearmint Bayesian优化运行,而不必在每个worker运行。
另一个替代方法是使用StarCluster,它是由麻省理工大学为AWS EC2开发的一个开源集群计算框架。StarCluster以一种容错性方式运行在Oracle Grid Engine 上(以前是 Sun Grid Engine),完全由Spearmint支持。最后,我们还在研究,将Spearmint 和 Jobman 整合以便更好地管理hyperparameter搜索工作流。下图是使用Spearmint plus Celery、 Condor或是StarCluster的一般设置:
结语
使用GPU实现前沿解决方案,比如训练大规模神经网络需要艰苦的努力。如果你需要在自己定制的基础设施上实现它、成本和复杂性将不可思议的。利用AWS有明显的好处,在实例的定制和使用资源时会有一定的支持。我们希望通过分享我们的经验来让别人更方便开发类似应用程序。




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
