上一次我们讨论了一下关于GPU在处理大数据的可能性,今天我们来猜想一下Hadoop+GPU来处理大数据。
Hadoop
一个分布式系统基础架构,由Apache基金会所开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
GPU就不多说了,下面我们看看它是怎么工作的:
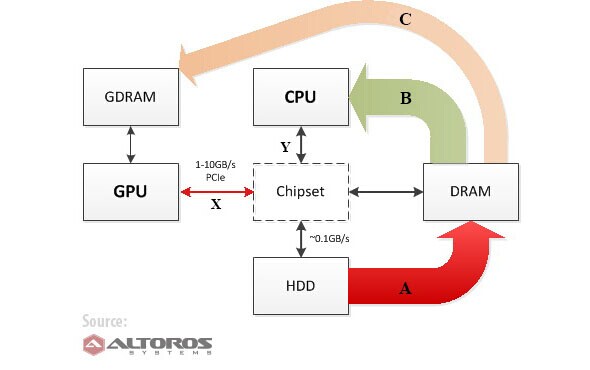
A:传输数据从一个硬盘DRAM(一种常见的初始步骤CPU和GPU计算)
B:处理数据和CPU(传输数据:DRAM→芯片组→CPU)
C:处理数据(数据传输:DRAM→CPU芯片→→芯片组→GPU→GDRAM→GPU)
不知道大家对这种方式有什么看法呢?可以讨论一下哟!~~




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享











