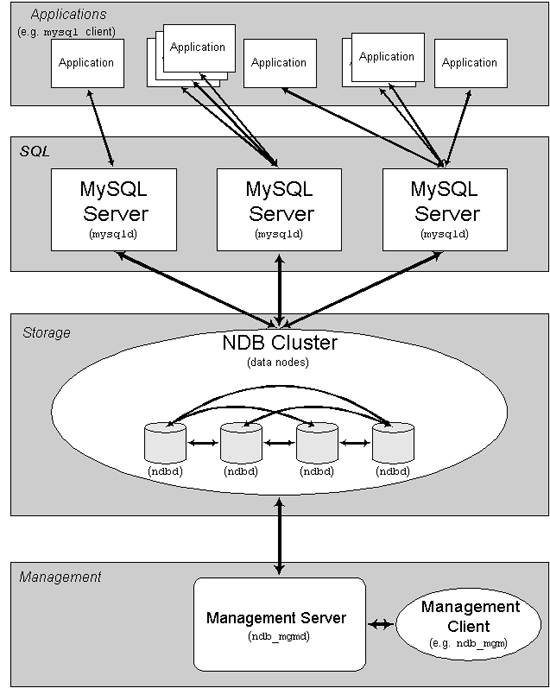
其实MYSQL的官方免费手册中就有解释。 可以把内容复制到在线翻译中进行翻译。 引用Management node: The role of this type of node is to manage the other nodes within the MySQL Cluster, performing such functions as providing configuration data, starting and stopping nodes, running backup, and so forth. Because this node type manages the configuration of the other nodes, a node of this type should be started first, before any other node. An MGM node is started with the command ndb_mgmd. Data node: This type of node stores cluster data. There are as many data nodes as there are replicas, times the number of fragments (see Section 17.1.2, “MySQL Cluster Nodes, Node Groups, Replicas, and Partitions”). For example, with two replicas, each having two fragments, you need four data nodes. One replica is sufficient for data storage, but provides no redundancy; therefore, it is recommended to have 2 (or more) replicas to provide redundancy, and thus high availability. A data node is started with the command ndbd (see Section 17.4.1, “ndbd — The MySQL Cluster Data Node Daemon”). In MySQL Cluster NDB 7.0 and later, ndbmtd can also be used for the data node process; see Section 17.4.3, “ndbmtd — The MySQL Cluster Data Node Daemon (Multi-Threaded)”, for more information. MySQL Cluster tables are normally stored completely in memory rather than on disk (this is why we refer to MySQL Cluster as an in-memory database). In MySQL 5.1, MySQL Cluster NDB 6.X, and later, some MySQL Cluster data can be stored on disk; see Section 17.5.12, “MySQL Cluster Disk Data Tables”, for more information. SQL node: This is a node that accesses the cluster data. In the case of MySQL Cluster, an SQL node is a traditional MySQL server that uses the NDBCLUSTER storage engine. An SQL node is a mysqld process started with the --ndbcluster and --ndb-connectstring options, which are explained elsewhere in this chapter, possibly with additional MySQL server options as well. An SQL node is actually just a specialized type of API node, which designates any application which accesses MySQL Cluster data. Another example of an API node is the ndb_restore utility that is used to restore a cluster backup. It is possible to write such applications using the NDB API. For basic information about the NDB API, see Getting Started with the NDB API.
Management node: The role of this type of node is to manage the other nodes within the MySQL Cluster, performing such functions as providing configuration data, starting and stopping nodes, running backup, and so forth. Because this node type manages the configuration of the other nodes, a node of this type should be started first, before any other node. An MGM node is started with the command ndb_mgmd. Data node: This type of node stores cluster data. There are as many data nodes as there are replicas, times the number of fragments (see Section 17.1.2, “MySQL Cluster Nodes, Node Groups, Replicas, and Partitions”). For example, with two replicas, each having two fragments, you need four data nodes. One replica is sufficient for data storage, but provides no redundancy; therefore, it is recommended to have 2 (or more) replicas to provide redundancy, and thus high availability. A data node is started with the command ndbd (see Section 17.4.1, “ndbd — The MySQL Cluster Data Node Daemon”). In MySQL Cluster NDB 7.0 and later, ndbmtd can also be used for the data node process; see Section 17.4.3, “ndbmtd — The MySQL Cluster Data Node Daemon (Multi-Threaded)”, for more information. MySQL Cluster tables are normally stored completely in memory rather than on disk (this is why we refer to MySQL Cluster as an in-memory database). In MySQL 5.1, MySQL Cluster NDB 6.X, and later, some MySQL Cluster data can be stored on disk; see Section 17.5.12, “MySQL Cluster Disk Data Tables”, for more information. SQL node: This is a node that accesses the cluster data. In the case of MySQL Cluster, an SQL node is a traditional MySQL server that uses the NDBCLUSTER storage engine. An SQL node is a mysqld process started with the --ndbcluster and --ndb-connectstring options, which are explained elsewhere in this chapter, possibly with additional MySQL server options as well. An SQL node is actually just a specialized type of API node, which designates any application which accesses MySQL Cluster data. Another example of an API node is the ndb_restore utility that is used to restore a cluster backup. It is possible to write such applications using the NDB API. For basic information about the NDB API, see Getting Started with the NDB API.
57,065
社区成员
56,762
社区内容
加载中
试试用AI创作助手写篇文章吧



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

