

34,875
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
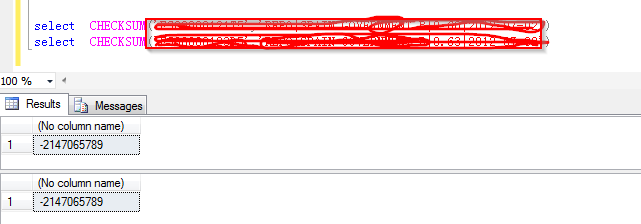

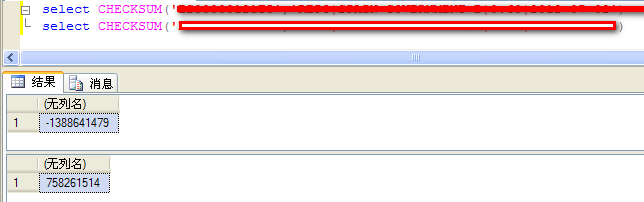
DECLARE
@guid1 UNIQUEIDENTIFIER,
@guid2 UNIQUEIDENTIFIER,
@i int
set @i=0
while(@i<10000000)
begin
set @guid1=NEWID()
set @guid2=NEWID()
if(CHECKSUM(@guid1)=checksum(@guid2))
begin
print @guid1
print @guid2
end
set @i=@i+1
end



