Oracle中组合索引建立的顺序疑问
我今天看有关SQL优化的内容,其中提到建立组合索引最好是将 经常等值查询的列放在前面
例如 表中有 name, time 两个字段,name经常被等值查询,time经常被范围查询
那么如果需要将这两个字段建组合索引的时候,就应该建成(name, time)这样的顺序
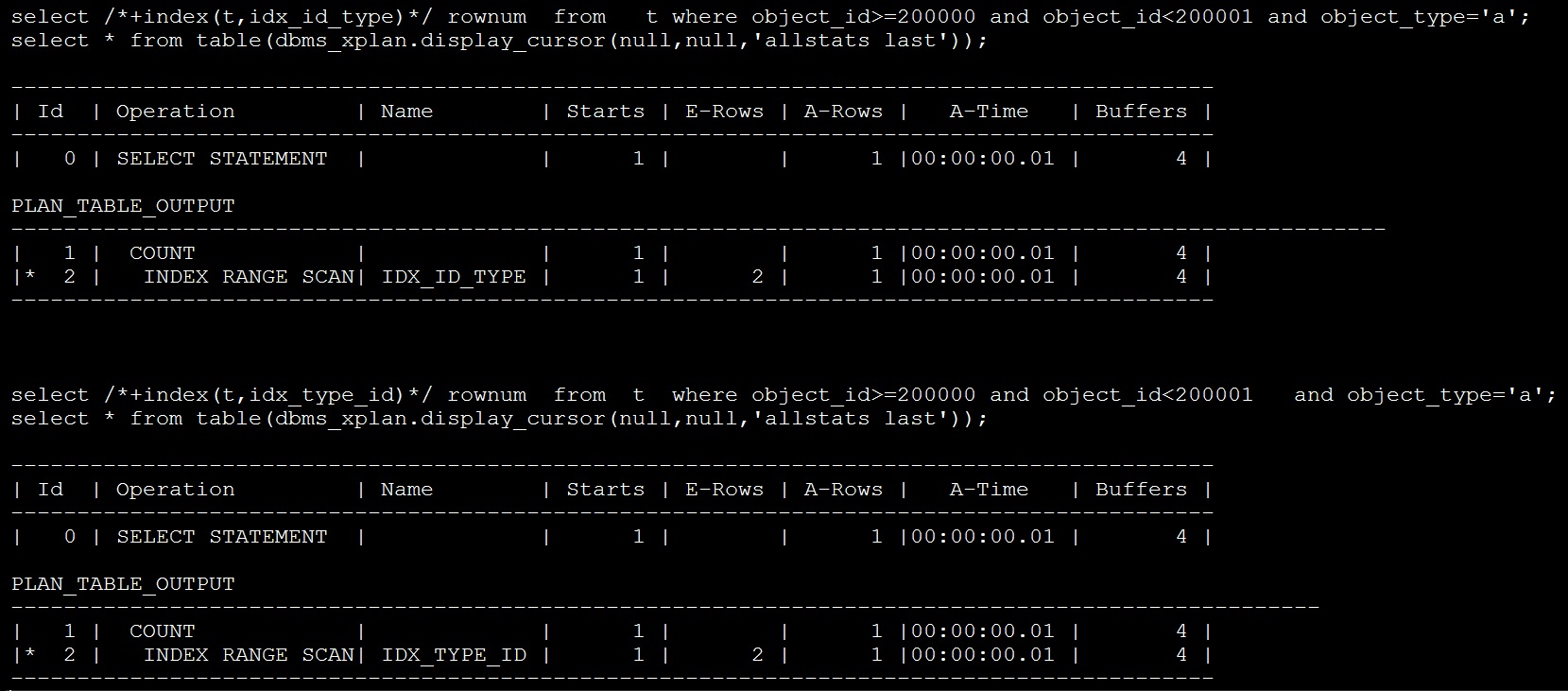
给出的解释是:因为索引都是有序的,组合索引根据前导列排序,也就是name排序;如果查询name=abc,当Oracle看到name=b~~的就可以认为后面再无abc了,就不继续往下找了
例如查询 name=abc and time>2007 and time < 2014
Oracle会从name往下扫描,当扫描到aca就会停止扫描,即便name=abc的记录对应的time只有2008,2009其他年份都没有,Oracle也不会继续往后找了
但是如果建立成(time, name)索引中按照time排序,那么Oracle 就会遍历time = 2008,2009,2010,2011,2012,2013
即便2010~2013都没有name=abc的情况,Oracle也会都遍历到
所以建立组合索引要把经常等值查询的放前面
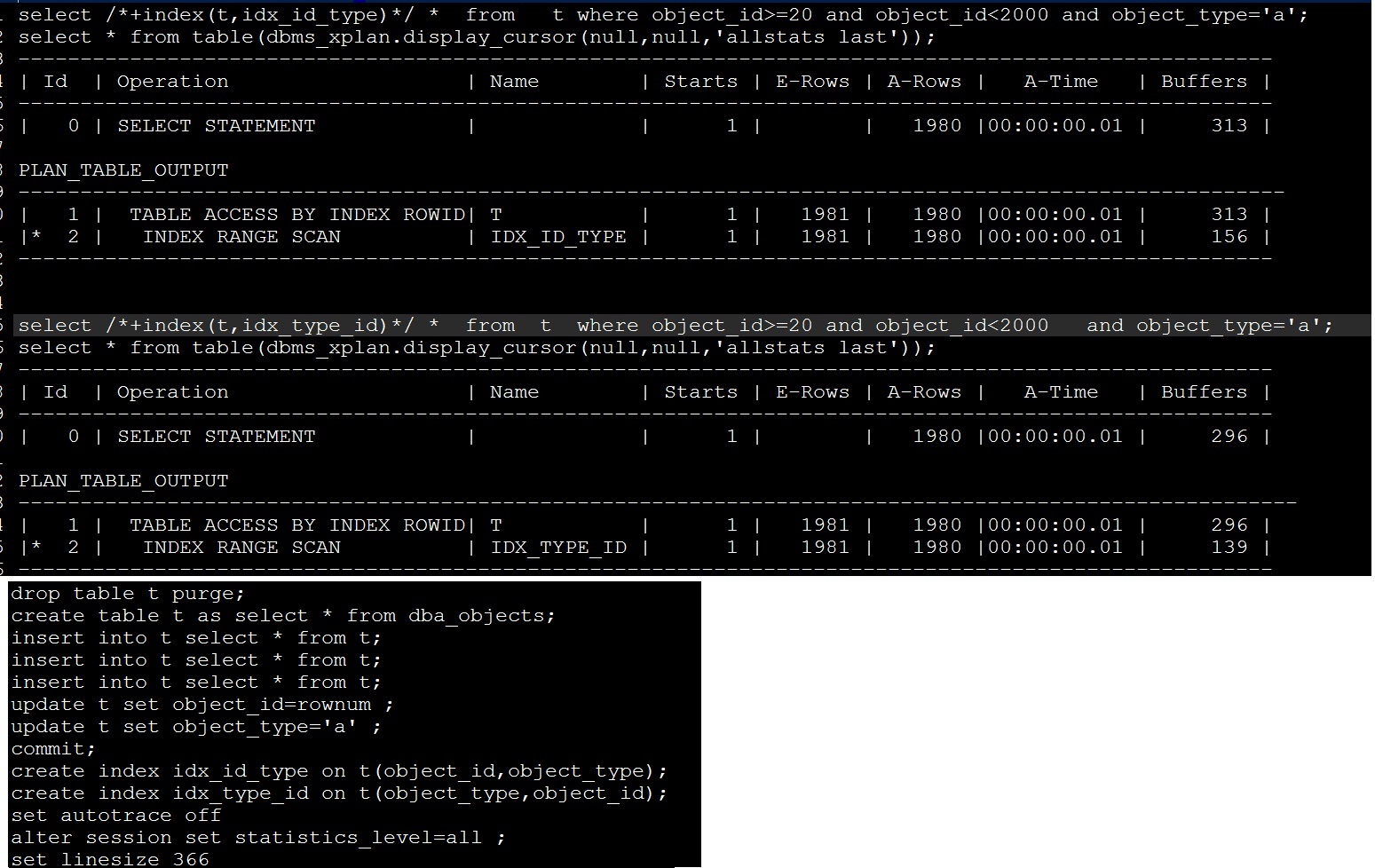
但是对于这个解释我就有疑问了,我觉得不一定吧,我考虑了一个极端情况
表中的name全是abc,那如果再建立(name, time)这样的索引,不就出现不了他说的到aca自动停止的情况了?这不就相当于遍历全部索引了?
如果建成(time,name)这不就反倒对扫描范围有所限定了?
当然了,我说的这个极端情况加name=abc根本是没意义的,只是就事论事,不考虑与这个问题无关的事
但是我自己做了个试验,我往一个表中插了50万数据,我把所有的name全设定成abc,结果却出乎我意料了,依旧是(name,time)性能更好,而不是我想的那种情况,请问这是为什么?还是我对组合索引的查询原理理解有误? 请指教



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享