服务器配置:阿里云4核U 4G内存
数据库中有张表 里面有100多万的数据,客户端的所有应用程序都在同时且时刻刻的不断的随机查询这张表的一条数据
表结构字段:
ID
IDName
Username
UserPWD
Department
Isvalid
======================================
查了下会话一般客户端有100条会话连接
查询资源的消耗情况如下图:
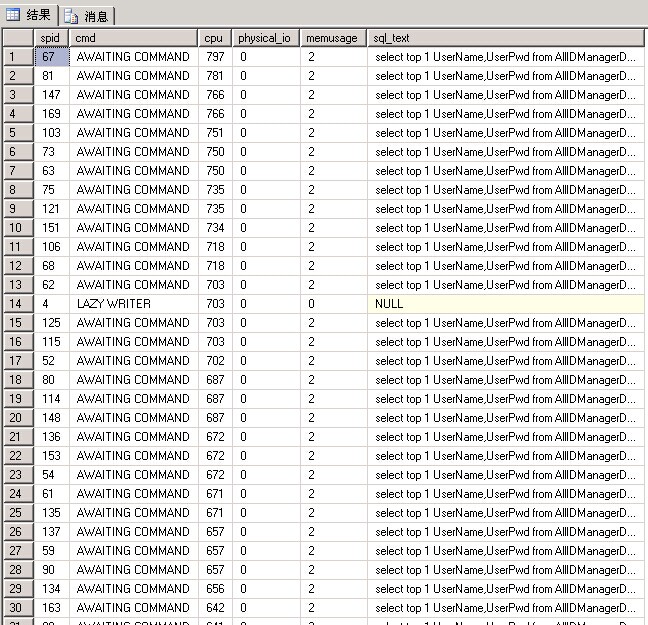

那条SQL语句无非就是一条随机从这张表里面查询一条数据的语句 如下
select top 1 UserName,UserPwd from AllIDManagerDetails where IDName='VIP' and Isvalid=0 order by newid()
=================================================
请问各位有什么办法能做到把CPU资源降低下来?在IDName上建立索引会好些么?
或者升级硬件?


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享





