

34,876
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享




create procedure [randrecord](@randID int)
as
SELECT TOP 1 *
FROM (
SELECT TOP 1
UserName ,
UserPwd
FROM AllIDManagerDetails
WHERE IDName = 'VIP'
AND Isvalid = 0
AND ID >= @randID
ORDER BY ID
UNION ALL
SELECT TOP 1
UserName ,
UserPwd
FROM AllIDManagerDetails
WHERE IDName = 'VIP'
AND Isvalid = 0
ORDER BY ID
) T
ORDER BY ID DESC
/*
确保索引覆盖
索引列IDName,Isvalid,包含列 UserName,UserPwd(如果ID不是聚集索引还需包含ID字段)
*/
SELECT a.UserName,
UserPwd
FROM
(SELECT ROW_NUMBER() OVER(ORDER BY ID DESC) id,
UserName,
UserPwd
FROM dbo.AllIDManagerDetails
WHERE IDName='VIP' and Isvalid=0)a,
(SELECT cast (RAND() * COUNT(*)+1 AS INT) id FROM dbo.AllIDManagerDetails
WHERE IDName='VIP' and Isvalid=0)b
WHERE a.id=b.idcreate procedure [randrecord](@randID int)
as
SELECT TOP 1
UserName ,
UserPwd
FROM AllIDManagerDetails
WHERE IDName = 'VIP'
AND Isvalid = 0
AND ID >= @randID

create procedure [randrecord](@randID int)
as
SELECT TOP 1
UserName ,
UserPwd
FROM AllIDManagerDetails
WHERE IDName = 'VIP'
AND Isvalid = 0
AND ID >= @randIDselect top 1000 UserName,UserPwd from AllIDManagerDetails where IDName='VIP' and Isvalid=0 order by newid()
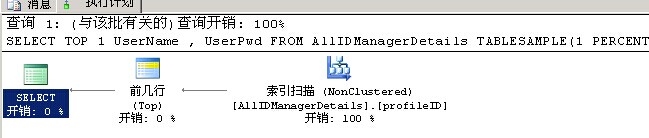
SELECT TOP 1
UserName ,
UserPwd
FROM AllIDManagerDetails TABLESAMPLE(1 PERCENT)
WHERE IDName = 'VIP'
and Isvalid = 0 --order by newid()

