win下eclipse是在本地跑mapreduce作业,而不是在虚拟机的hadoop中,如何解决?
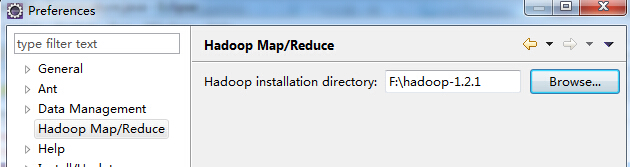
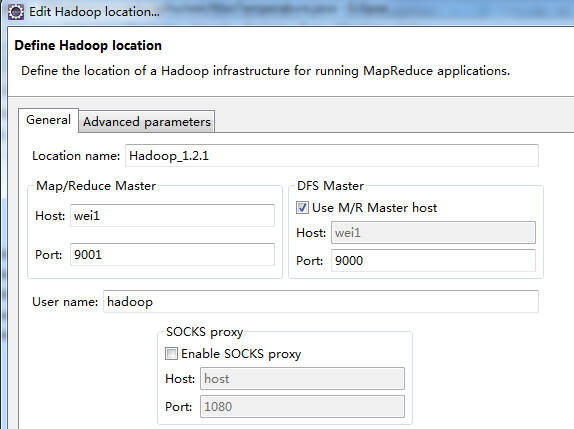
虚拟机中的hadoop版本是1.2.1。windows的eclipse已经配置好hadoop插件,也能通过插件正常访问虚拟机中的hdfs文件。但运行作业时发现mapreduce作业是在本地运行的,是将虚拟机中的hdfs的数据下载到本机进行分析,分析好再上传到虚拟机的hdfs中,而虚拟机的CPU使用率压根没有升高过。请问怎样解决?谢谢!
运行时的输出如下:
14/08/22 11:59:30 INFO util.NativeCodeLoader: Loaded the native-hadoop library
14/08/22 11:59:30 ERROR nativeio.NativeIO: Unable to initialize NativeIO libraries
java.lang.NoClassDefFoundError: org/apache/hadoop/io/nativeio/NativeIO$POSIX$Stat
at org.apache.hadoop.io.nativeio.NativeIO.initNative(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO.<clinit>(NativeIO.java:89)
at org.apache.hadoop.fs.FileUtil.setPermission(FileUtil.java:655)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:514)
at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:349)
at org.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:193)
at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:126)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:942)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:936)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1190)
at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:936)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:550)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:580)
at cn.wei.MaxTemperature.main(MaxTemperature.java:29)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.io.nativeio.NativeIO$POSIX$Stat
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
... 16 more
14/08/22 11:59:30 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
14/08/22 11:59:30 WARN mapred.JobClient: No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String).
14/08/22 11:59:30 INFO input.FileInputFormat: Total input paths to process : 1
14/08/22 11:59:30 WARN snappy.LoadSnappy: Snappy native library not loaded
14/08/22 11:59:30 INFO mapred.JobClient: Running job: job_local1393432176_0001
14/08/22 11:59:30 INFO mapred.LocalJobRunner: Waiting for map tasks
14/08/22 11:59:30 INFO mapred.LocalJobRunner: Starting task: attempt_local1393432176_0001_m_000000_0
14/08/22 11:59:31 INFO mapred.Task: Using ResourceCalculatorPlugin : null
14/08/22 11:59:31 INFO mapred.MapTask: Processing split: hdfs://wei1:9000/user/hadoop/climate_data_20140101_20140807.txt:0+33554432
14/08/22 11:59:31 INFO mapred.MapTask: io.sort.mb = 100
14/08/22 11:59:31 INFO mapred.MapTask: data buffer = 79691776/99614720
14/08/22 11:59:31 INFO mapred.MapTask: record buffer = 262144/327680
14/08/22 11:59:31 INFO mapred.JobClient: map 0% reduce 0%
14/08/22 11:59:37 INFO mapred.LocalJobRunner:
14/08/22 11:59:40 INFO mapred.LocalJobRunner:
14/08/22 11:59:40 INFO mapred.JobClient: map 1% reduce 0%



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享