


22,209
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

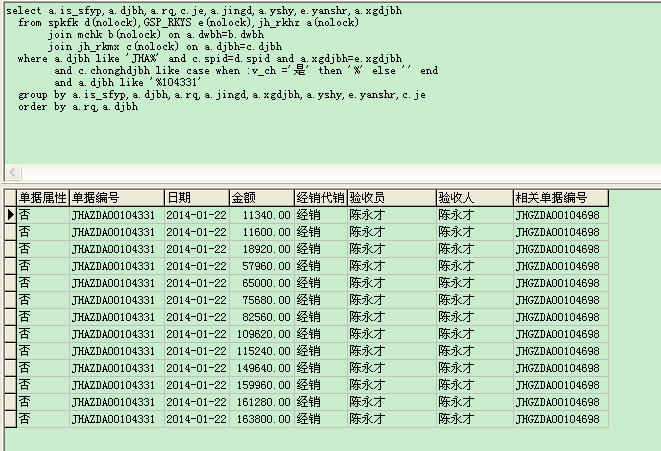
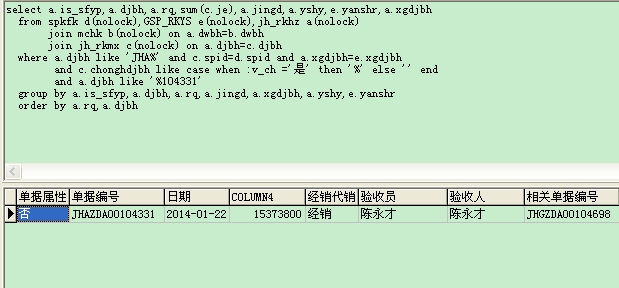
 这样不会重复,但是要怎么汇总起来呢[/quote]你去掉截图中的最后group by那句看看是不是重复,如果是,就要预先去重
这样不会重复,但是要怎么汇总起来呢[/quote]你去掉截图中的最后group by那句看看是不是重复,如果是,就要预先去重


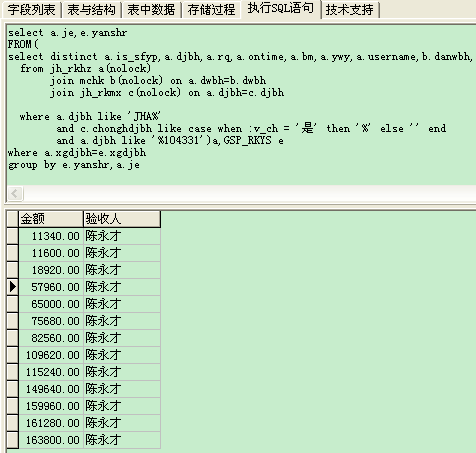
SELECT a.is_sfyp,a.djbh,a.rq,SUM(a.je) je,a.jingd,a.yshy,a.yanshr,a.xgdjbh
FROM (
select distinct a.is_sfyp,a.djbh,a.rq,c.je,a.jingd,a.yshy,e.yanshr,a.xgdjbh
from jh_rkhz a(nolock)
join mchk b(nolock) on a.dwbh=b.dwbh
join jh_rkmx c(nolock) on a.djbh=c.djbh
join GSP_RKYS e(nolock) on a.xgdjbh=e.xgdjbh
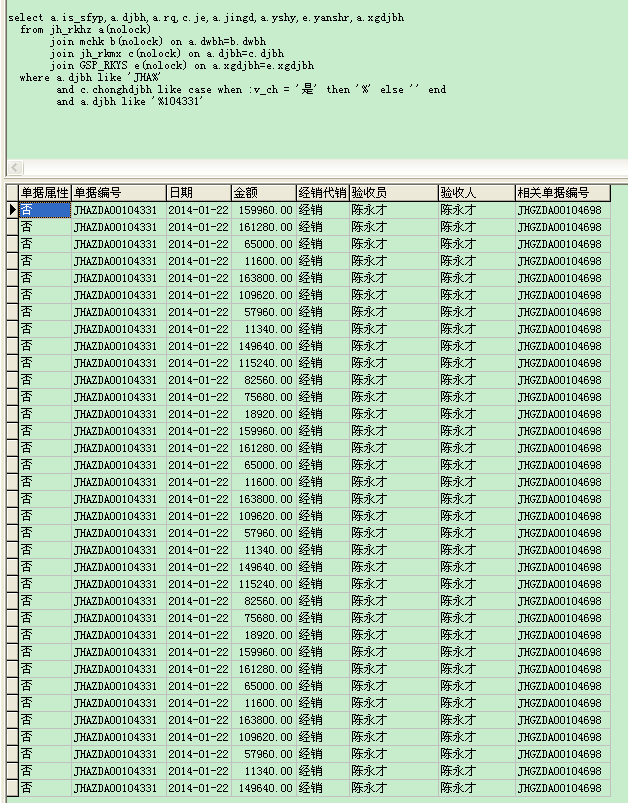
where a.djbh like 'JHA%'
and c.chonghdjbh like case when :v_ch = '是' then '%' else '' end
and a.djbh like '%104331'
)a
group by a.is_sfyp,a.djbh,a.rq,a.jingd,a.xgdjbh,a.yshy,a.yanshr