



3,491
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享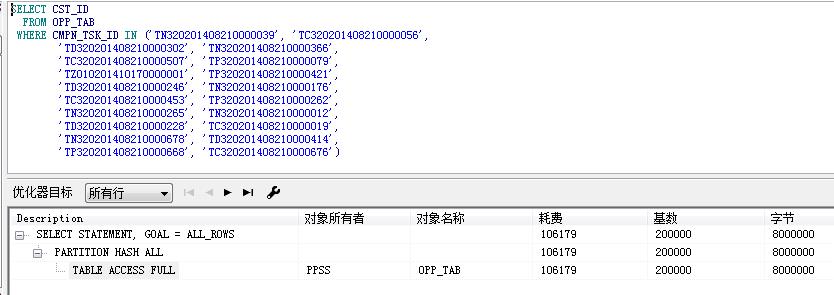
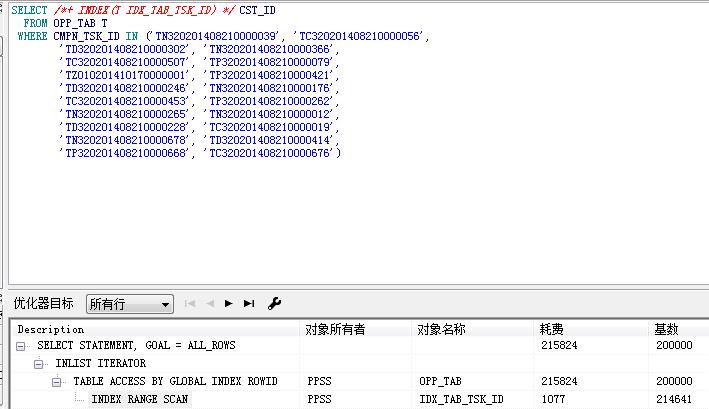
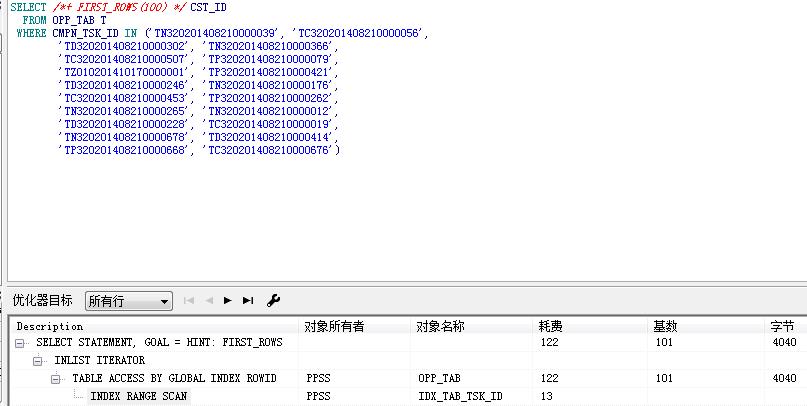
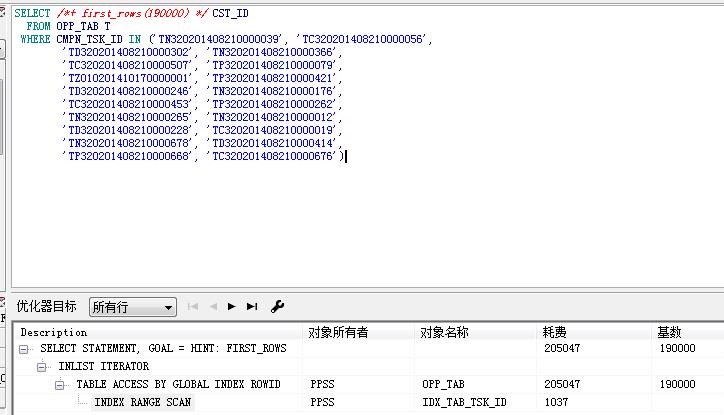
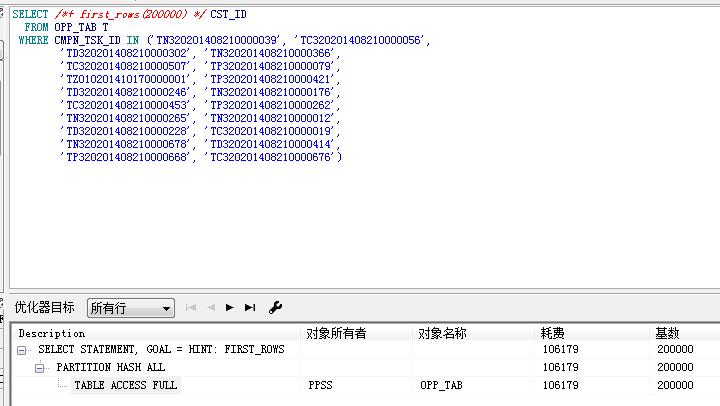
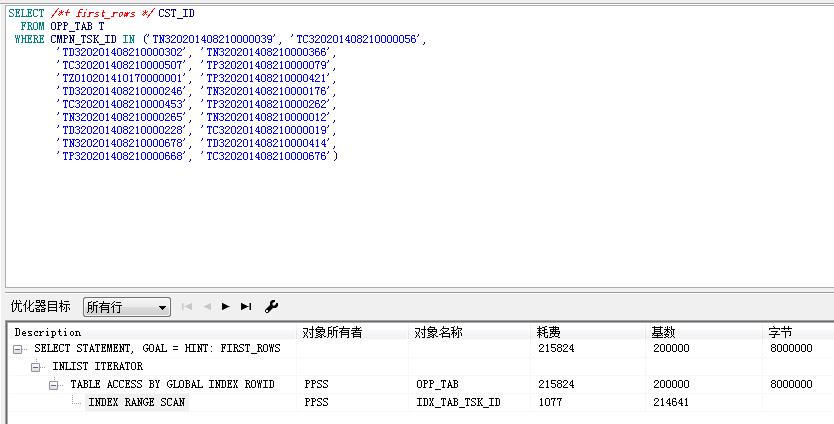



SQL> create table test_opp_tab as
2 select trunc(rownum/1000) a,'test' b,'testtest' c
3 from dual
4 connect by rownum<=1000000
5 /
Table created
SQL> create index idx_test_opp_tab_a on test_opp_tab(a)
2 /
Index createdselect c
from test_opp_tab
where a between 100 and 500SQL> select /*+ first_rows(100)*/c
2 from test_opp_tab
3 where a between 100 and 500
4 /
401000 rows selected.
Elapsed: 00:00:36.43
Execution Plan
----------------------------------------------------------
Plan hash value: 1393809933
--------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost(%CPU)| Time |
--------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 434K| 9756K| 4 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| TEST_OPP_TAB | 434K| 9756K| 4 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_TEST_OPP_TAB_A | | | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("A">=100 AND "A"<=500)
Note
-----
- dynamic sampling used for this statement
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
55521 consistent gets
0 physical reads
0 redo size
11570850 bytes sent via SQL*Net to client
294401 bytes received via SQL*Net from client
26735 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
401000 rows processed
SQL> select c
2 from test_opp_tab
3 where a between 100 and 500
4 /
401000 rows selected.
Elapsed: 00:00:34.14
Execution Plan
----------------------------------------------------------
Plan hash value: 3495120256
----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 434K| 9756K| 736 (4)| 00:00:09 |
|* 1 | TABLE ACCESS FULL| TEST_OPP_TAB | 434K| 9756K| 736 (4)| 00:00:09 |
----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("A">=100 AND "A"<=500)
Note
-----
- dynamic sampling used for this statement
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
29842 consistent gets
0 physical reads
0 redo size
4304387 bytes sent via SQL*Net to client
294401 bytes received via SQL*Net from client
26735 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
401000 rows processedSQL> create table test_opp_tab as
2 select trunc(rownum/1000) a,'test' b,'testtest' c
3 from dual
4 connect by rownum<=1000000
5 /
Table created
SQL> create index idx_test_opp_tab_a on test_opp_tab(a)
2 /
Index createdselect c
from test_opp_tab
where a between 100 and 500SQL> select /*+ first_rows(100)*/c
2 from test_opp_tab
3 where a between 100 and 500
4 /
401000 rows selected.
Elapsed: 00:00:36.43
Execution Plan
----------------------------------------------------------
Plan hash value: 1393809933
--------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost(%CPU)| Time |
--------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 434K| 9756K| 4 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| TEST_OPP_TAB | 434K| 9756K| 4 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_TEST_OPP_TAB_A | | | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("A">=100 AND "A"<=500)
Note
-----
- dynamic sampling used for this statement
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
55521 consistent gets
0 physical reads
0 redo size
11570850 bytes sent via SQL*Net to client
294401 bytes received via SQL*Net from client
26735 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
401000 rows processed
SQL> select c
2 from test_opp_tab
3 where a between 100 and 500
4 /
401000 rows selected.
Elapsed: 00:00:34.14
Execution Plan
----------------------------------------------------------
Plan hash value: 3495120256
----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 434K| 9756K| 736 (4)| 00:00:09 |
|* 1 | TABLE ACCESS FULL| TEST_OPP_TAB | 434K| 9756K| 736 (4)| 00:00:09 |
----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("A">=100 AND "A"<=500)
Note
-----
- dynamic sampling used for this statement
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
29842 consistent gets
0 physical reads
0 redo size
4304387 bytes sent via SQL*Net to client
294401 bytes received via SQL*Net from client
26735 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
401000 rows processed
SQL> create table test_opp_tab as
2 select trunc(rownum/1000) a,'test' b,'testtest' c
3 from dual
4 connect by rownum<=1000000
5 /
Table created
SQL> create index idx_test_opp_tab_a on test_opp_tab(a)
2 /
Index createdselect c
from test_opp_tab
where a between 100 and 500SQL> select /*+ first_rows(100)*/c
2 from test_opp_tab
3 where a between 100 and 500
4 /
401000 rows selected.
Elapsed: 00:00:36.43
Execution Plan
----------------------------------------------------------
Plan hash value: 1393809933
--------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost(%CPU)| Time |
--------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 434K| 9756K| 4 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| TEST_OPP_TAB | 434K| 9756K| 4 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_TEST_OPP_TAB_A | | | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("A">=100 AND "A"<=500)
Note
-----
- dynamic sampling used for this statement
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
55521 consistent gets
0 physical reads
0 redo size
11570850 bytes sent via SQL*Net to client
294401 bytes received via SQL*Net from client
26735 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
401000 rows processed
SQL> select c
2 from test_opp_tab
3 where a between 100 and 500
4 /
401000 rows selected.
Elapsed: 00:00:34.14
Execution Plan
----------------------------------------------------------
Plan hash value: 3495120256
----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 434K| 9756K| 736 (4)| 00:00:09 |
|* 1 | TABLE ACCESS FULL| TEST_OPP_TAB | 434K| 9756K| 736 (4)| 00:00:09 |
----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("A">=100 AND "A"<=500)
Note
-----
- dynamic sampling used for this statement
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
29842 consistent gets
0 physical reads
0 redo size
4304387 bytes sent via SQL*Net to client
294401 bytes received via SQL*Net from client
26735 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
401000 rows processed



