社区
PHP
帖子详情
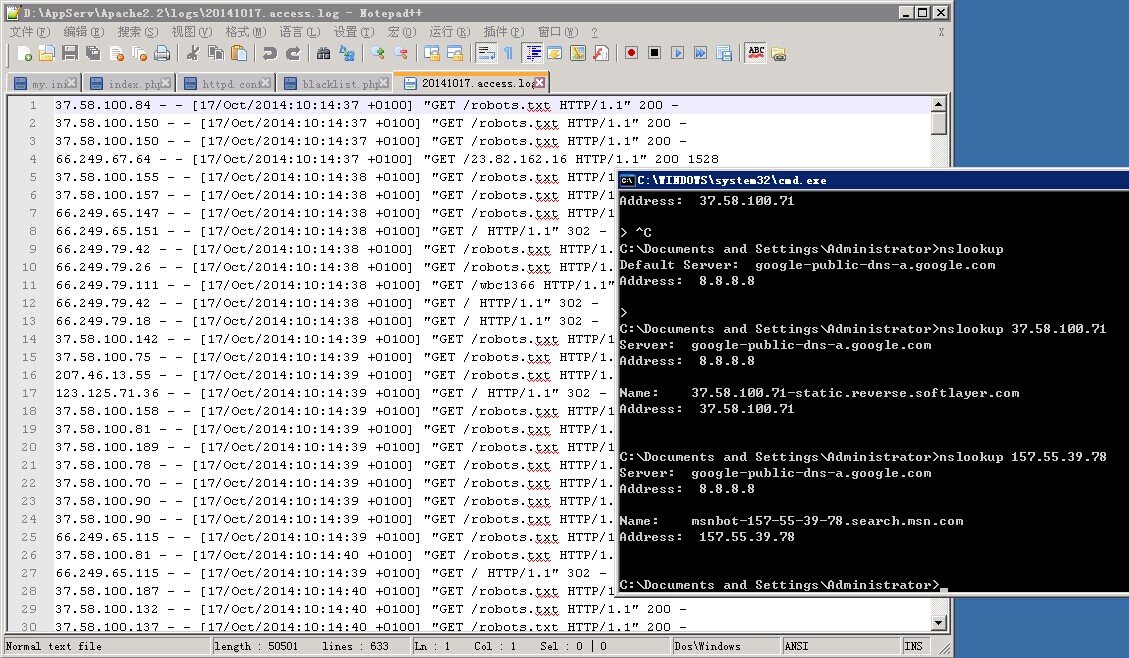
超多IP访问/robots.txt
u012914916
2014-10-17 05:22:11
apache日志里全是这样的记录,全是访问的/robots.txt,而且十多分钟就有几万行。服务器CPU经常跑到100%。
蜘蛛也不会爬robots.txt这么频繁吧。。。大神帮分析下
66.249.65.147 - - [17/Oct/2014:10:14:38 +0100] "GET /robots.txt HTTP/1.1" 200 -
(-是因为我在网站根目录下创建了个空白的robots.txt。)
...全文
482
2
打赏
收藏
超多IP访问/robots.txt
apache日志里全是这样的记录,全是访问的/robots.txt,而且十多分钟就有几万行。服务器CPU经常跑到100%。 蜘蛛也不会爬robots.txt这么频繁吧。。。大神帮分析下 66.249.65.147 - - [17/Oct/2014:10:14:38 +0100] "GET /robots.txt HTTP/1.1" 200 - (-是因为我在网站根目录下创建了个空白的robots.txt。)
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
2 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
晓敬
2014-10-20
打赏
举报
回复
robots.txt这个东西只要你编程谨慎没必要放上,放上了是个累赘,分析一下他的坏处,欢迎拍砖: 1、如果你没有将后台的地址在前台页面上调用过的话,蜘蛛是不会爬取的,对于css,js这种东西,蜘蛛也不愿意爬。 2、很多新手在设置robots.txt的时候都是很乖很听话,敏感地址放上来屏蔽蜘蛛爬取,其实只要严格,蜘蛛爬不到,但是别有用心的人会先看robots.txt一下就找到了管理入口地址。 3、不管哪个蜘蛛跑过来第一个爬的就是robot.txt,占用了一点资源 你这种情况应该不是robots.txt的原因,这个文件应该是直接发出去的,到不了100%的情况
傲雪星枫
2014-10-18
打赏
举报
回复
比较奇怪,你确定cpu被占100%是这个问题? 把robots.txt屏蔽看看。
爬取彼岸图网的壁纸 https://pic.netbian.com/
它包括发送HTTP请求、解析HTML响应、处理反爬机制(如
robots.txt
、验证码、
IP
限制等)以及数据存储等步骤。 2. **Python爬虫框架**:Python是最常用的语言之一用于编写爬虫,如Scrapy和BeautifulSoup。Scrapy是一个...
Python爬虫入门教程:超级简单的Python爬虫教程.pdf
- **示例**:以淘宝网为例,可以在浏览器中
访问
`https://www.taobao.com/
robots.txt
` 来查看其`
robots.txt
`文件。 - **内容解释**:例如: ``` User-Agent: * Disallow: / ``` - **User-Agent:** 表示所有...
PHP代码实现爬虫记录——超管用
这个系统的主要目标是监控和记录
访问
网站的搜索引擎爬虫,以便收集和分析这些爬虫的信息。首先,我们需要创建一个名为`...同时,要注意遵循
robots.txt
文件规定,尊重网站的抓取规则,确保合法合规地进行网络爬虫活动。
网络爬虫课程设计文档.pdf
然而,合法和道德的爬虫行为需要遵守网站的
robots.txt
规则,尊重版权,避免对目标服务器造成过大的
访问
压力。同时,随着网站反爬机制的升级,爬虫技术也需要不断更新和优化,如使用代理
IP
、模拟浏览器行为、处理...
从网上抓取指定URL源码的方案
网站可能通过设置
robots.txt
文件来限制爬虫的
访问
,或者采用验证码、
IP
限制、User-Agent检测等方式来阻止非人类的
访问
。针对这些策略,我们可以采取以下对策: 1. **遵守
robots.txt
**:在开始抓取前,检查并遵循...
PHP
20,396
社区成员
19,657
社区内容
发帖
与我相关
我的任务
PHP
“超文本预处理器”,是在服务器端执行的脚本语言,尤其适用于Web开发并可嵌入HTML中。PHP语法利用了C、Java和Perl,该语言的主要目标是允许web开发人员快速编写动态网页。
复制链接
扫一扫
分享
社区描述
“超文本预处理器”,是在服务器端执行的脚本语言,尤其适用于Web开发并可嵌入HTML中。PHP语法利用了C、Java和Perl,该语言的主要目标是允许web开发人员快速编写动态网页。
php
phpstorm
技术论坛(原bbs)
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享




