1. 关于hadoop中的map过程,我的理解是每一个map系统会开启一个JVM进程来处理,map之间相互并行,map函数内串行。这样的想法是否正确?
2. 由于想在hadoop集群上算一个初始输入数据不多,但是计算很复杂的程序,希望通过mapreduce来达到并行计算的目的。可以通过job.setNumReduceTasks(0);语句设置reduce个数为0,只使用map来计算。但是设置map的个数时遇到了问题:新的API中job没有类似setNumMapTasks()这样的方法; 在运行时加入参数-D mapreduce.map.tasks=2这样的参数也无效。
查过好多资料,好像是说map的个数取决于block_size、total_size等参数。但是都说的是1.x版本的设置,hadoop 2.2.0上并没有找到mapred.map.tasks、mapred.min.split.size等对应的设置方法。
由于我的输入文件只有一个文件,而且不算是“大数据”,只是单纯想在hadoop上实现并行,所以我希望能够设置一个最少的map数目,以便能在各个计算节点上并行。请问我应该如何设置?
******
3. 我通过手动将输入文件分为4份,使得hadoop的确生成了4个map,但是Web UI显示的结果如下:
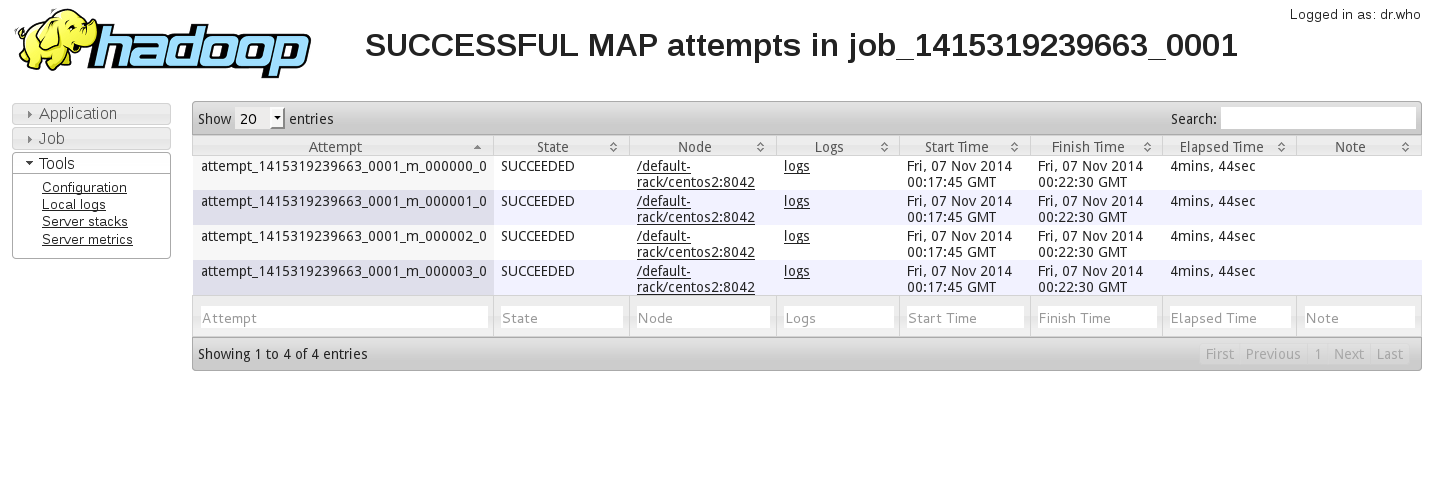
我的集群有两台nodemanager, 但好像4个map任务都运行在了一台机器上,这是怎么回事?如何才能使map均匀的分配在两台机器上?
另外,我的配置文件基本上是默认的,也就是说mapreduce.job.maps为默认值“2” , mapreduce.tasktracker.map.tasks.maximum也为默认值“2”, 不可能存在一个节点上四个map的情况啊?这两个配置参数究竟是如何影响程序的?


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享





