目的:获得商品的促销价格(实时价格)
我的思路:
以下面这个链接为例:
http://item.taobao.com/item.htm?spm=a230r.1.14.72.OJMBD3&id=42302206603&ns=1&abbucket=11#detail
点击F12开发者工具,点击network
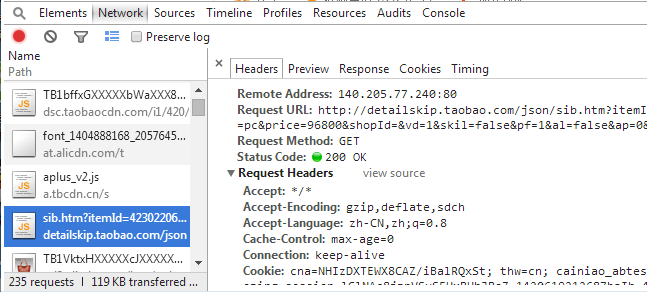
点击蓝色框中的链接,就可以进入到下面页面:
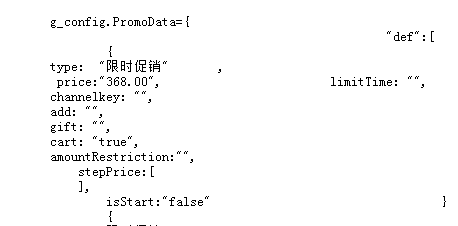
这样就能获取到促销的价格了
但
问题是,上面能够显示促销价格的页面,当我把他的地址复制后,在一个新的页面中无法打开,好桑心!这是熟么问题呢?求大神们指导

那个无法打开的网址:
http://detailskip.taobao.com/json/sib.htm?itemId=42302206603&sellerId=713417480&u=1&p=1&rcid=50006842&sts=471404544,1170936092094889988,216243150891548800,5136922622296067&chnl=pc&price=96800&shopId=&vd=1&skil=false&pf=1&al=false&ap=0&ss=0&free=1&st=1&ct=1&prior=1&ref=


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享





