



2,759
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
3 qid:1 1:1 2:1 3:0 4:0.2 5:0 # 1A
2 qid:1 1:0 2:0 3:1 4:0.1 5:1 # 1B
1 qid:1 1:0 2:1 3:0 4:0.4 5:0 # 1C
1 qid:1 1:0 2:0 3:1 4:0.3 5:0 # 1D
1 qid:2 1:0 2:0 3:1 4:0.2 5:0 # 2A
2 qid:2 1:1 2:0 3:1 4:0.4 5:0 # 2B
1 qid:2 1:0 2:0 3:1 4:0.1 5:0 # 2C
1 qid:2 1:0 2:0 3:1 4:0.2 5:0 # 2D
2 qid:3 1:0 2:0 3:1 4:0.1 5:1 # 3A
3 qid:3 1:1 2:1 3:0 4:0.3 5:0 # 3B
4 qid:3 1:1 2:0 3:0 4:0.4 5:1 # 3C
1 qid:3 1:0 2:1 3:1 4:0.5 5:0 # 3D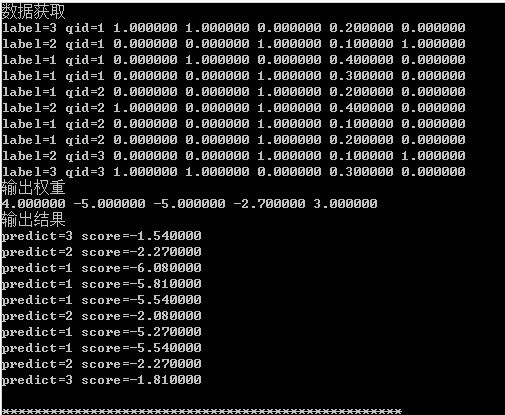
2 qid:31 1:3 2:0 3:2 4:0 5:3 6:1 7:0 8:0.666667 9:0 10:1 11:630 12:0 13:8 14:7 15:645 16:11.105542 17:24.506354 18:22.375632 19:24.51767 20:11.10342 21:23 22:0 23:2 24:0 25:25 26:6 27:0 28:0 29:0 30:7 31:10 32:0 33:1 34:0 35:10 36:7.666667 37:0 38:0.666667 39:0 40:8.333333 41:2.888889 42:0 43:0.222222 44:0 45:1.555556 46:0.036508 47:0 48:0.25000 49:0 50:0.03876 51:0.009524 52:0 53:0 54:0 55:0.010853 56:0.015873 57:0 58:0.12500 59:0 60:0.015504 61:0.012169 62:0 63:0.083333 64:0 65:0.01292 66:0.000007 67:0 68:0.003472 69:0 70:0.000004 71:87.798301 72:0 73:13.456976 74:0 75:94.287607 76:19.372463 77:0 78:0 79:0 80:22.135818 81:45.993884 82:0 83:6.868139 84:0 85:45.988976 86:29.26610 87:0 88:4.485659 89:0 90:31.429202 91:141.469454 92:0 93:10.073568 94:0 95:108.69628 96:1 97:0 98:0 99:0 100:1 101:0.975118 102:0 103:0.729751 104:0 105:0.98782 106:30.722513 107:0 108:12.917244 109:0 110:31.296026 111:-13.589865 112:-24.750609 113:-17.88018 114:-26.142408 115:-13.341415 116:-17.50694 117:-26.486177 118:-25.40009 119:-28.90753 120:-17.245469 121:-13.610241 122:-27.037812 123:-17.501184 124:-28.789803 125:-13.393425 126:2 127:31 128:0 129:0 130:289 131:23018 132:47 133:26 134:0 135:0 136:0
0 qid:31 1:3 2:0 3:0 4:0 5:3 6:1 7:0 8:0 9:0 10:1 11:2001 12:0 13:3 14:9 15:2013 16:11.105542 17:24.506354 18:22.375632 19:24.51767 20:11.10342 21:29 22:0 23:0 24:0 25:29 26:7 27:0 28:0 29:0 30:7 31:11 32:0 33:0 34:0 35:11 36:9.666667 37:0 38:0 39:0 40:9.666667 41:3.555556 42:0 43:0 44:0 45:3.555556 46:0.014493 47:0 48:0 49:0 50:0.014406 51:0.003498 52:0 53:0 54:0 55:0.003477 56:0.005497 57:0 58:0 59:0 60:0.005464 61:0.004831 62:0 63:0 64:0 65:0.004802 66:0.000001 67:0 68:0 69:0 70:0.000001 71:103.763409 72:0 73:0 74:0 75:103.742026 76:30.442441 77:0 78:0 79:0 80:30.43675 81:41.12525 82:0 83:0 84:0 85:41.112993 86:34.587803 87:0 88:0 89:0 90:34.580675 91:21.881433 92:0 93:0 94:0 95:21.849236 96:1 97:0 98:0 99:0 100:1 101:0.976409 102:0 103:0 104:0 105:0.976407 106:24.521332 107:0 108:0 109:0 110:24.65599 111:-16.286859 112:-24.750609 113:-24.450892 114:-26.142408 115:-16.304653 116:-18.090637 117:-26.486177 118:-26.747455 119:-28.90753 120:-18.099506 121:-16.372909 122:-27.037812 123:-27.040393 124:-28.789803 125:-16.39080 126:4 127:51 128:100 129:0 130:123 131:14160 132:3 133:4 134:0 135:0 136:0
1 qid:31 1:3 2:0 3:3 4:0 5:3 6:1 7:0 8:1 9:0 10:1 11:879 12:0 13:39 14:8 15:926 16:11.105542 17:24.506354 18:22.375632 19:24.51767 20:11.10342 21:60 22:0 23:13 24:0 25:73 26:4 27:0 28:1 29:0 30:5 31:50 32:0 33:11 34:0 35:61 36:20 37:0 38:4.333333 39:0 40:24.333333 41:450.666667 42:0 43:22.222222 44:0 45:672.888889 46:0.068259 47:0 48:0.333333 49:0 50:0.078834 51:0.004551 52:0 53:0.025641 54:0 55:0.00540 56:0.056883 57:0 58:0.282051 59:0 60:0.065875 61:0.022753 62:0 63:0.111111 64:0 65:0.026278 66:0.000583 67:0 68:0.01461 69:0 70:0.000785 71:263.471352 72:0 73:111.562202 74:0 75:320.530451 76:11.069979 77:0 78:6.588836 79:0 80:13.834886 81:229.969419 82:0 83:98.105226 84:0 85:280.532751 86:87.823784 87:0 88:37.187401 89:0 90:106.843484 91:10124.206537 92:0 93:1855.503751 94:0 95:15109.310465 96:1 97:0 98:1 99:0 100:1 101:0.772065 102:0 103:0.750994 104:0 105:0.770451 106:30.278456 107:0 108:19.57110 109:0 110:31.199275 111:-13.565396 112:-24.750609 113:-11.051469 114:-26.142408 115:-13.084904 116:-16.69777 117:-26.486177 118:-19.81613 119:-28.90753 120:-16.189522 121:-13.556924 122:-27.037812 123:-8.90722 124:-28.789803 125:-13.137813 126:2 127:65 128:109 129:0 130:2295 131:2911 132:28 133:64 134:0 135:0 136:0
0 qid:31 1:3 2:0 3:0 4:0 5:3 6:1 7:0 8:0 9:0 10:1 11:2331 12:0 13:13 14:4 15:2348 16:11.105542 17:24.506354 18:22.375632 19:24.51767 20:11.10342 21:26 22:0 23:0 24:0 25:26 26:3 27:0 28:0 29:0 30:3 31:19 32:0 33:0 34:0 35:19 36:8.666667 37:0 38:0 39:0 40:8.666667 41:53.555556 42:0 43:0 44:0 45:53.555556 46:0.011154 47:0 48:0 49:0 50:0.011073 51:0.001287 52:0 53:0 54:0 55:0.001278 56:0.008151 57:0 58:0 59:0 60:0.008092 61:0.003718 62:0 63:0 64:0 65:0.003691 66:0.00001 67:0 68:0 69:0 70:0.00001 71:110.645499 72:0 73:0 74:0 75:110.630165 76:8.302484 77:0 78:0 79:0 80:8.300932 81:87.388379 82:0 83:0 84:0 85:87.379054 86:36.881833 87:0 88:0 89:0 90:36.876722 91:1282.830789 92:0 93:0 94:0 95:1282.611524 96:1 97:0 98:0 99:0 100:1 101:0.823531 102:0 103:0 104:0 105:0.823555 106:20.565679 107:0 108:0 109:0 110:20.682866 111:-18.304699 112:-24.750609 113:-24.450892 114:-26.142408 115:-18.326239 116:-19.543987 117:-26.486177 118:-26.747455 119:-28.90753 120:-19.555363 121:-18.129064 122:-27.037812 123:-27.040393 124:-28.789803 125:-18.15067 126:1 127:21 128:0 129:0 130:14438 131:3761 132:63 133:56 134:0 135:10 136:36.15 //学习排序
public static void learningToRank(String filePath){
//变量
double index [] = new double[100];
double tao [] = new double[100];
int realRank;
int predictRank;
//初始化
for(int i=0;i<138;i++) {
weight[i] = 0; //权重初值
}
//阈值初值
for(int i=0; i<=(sumLabel+1) ; i++) {
if(i==0) b[i] = -1;
else if(i==(sumLabel+1)) b[i] = 10000;
else b[i] = 0;
}
//计算权重 学习算法
for(int iter = 0; iter<100000; ++iter) //迭代1万次
{
for(int i=1; i<=sumLabel ; ++i) //总样本数
{
//测试顺序
predictRank = 1;
for(int r=1; r<=(sumLabel+1); ++r) {
//权重*特征向量-阈值
double sumWF = 0;
for(int z=1; z<=136; z++) {
sumWF = sumWF + weight[z]*feature[i][z];
}
if(sumWF-b[r]<0) {
predictRank = r;
break;
}
} //for r
realRank = label[i];
if(realRank!=predictRank) {
for(int r=1; r<=sumLabel; r++) {
if(realRank<=r)
{
index[r] = -1;
}
else
{
index[r] = 1;
}
}
double tao_sum = 0.0;
for(int r=1; r<=sumLabel; r++) {
//权重*特征向量-阈值
double sumWF = 0;
for(int z=1; z<=136; z++) {
sumWF = sumWF + weight[z]*feature[i][z];
}
if((sumWF - b[r]) * index[r] <= 0) {
tao[r] = index[r];
} else {
tao[r] = 0;
}
tao_sum += tao[r];
}
//权重赋值
for(int z=1; z<=136; z++) {
weight[z] = weight[z] + tao_sum*feature[i][z];
}
for(int r=1;r<=sumLabel;++r) {
b[r] = b[r] - tao[r];
}
}
} //sumLabel
} //迭代1万次
//输出权重
System.out.println("输出权重");
for(int i=1;i<=136;i++)
{
System.out.println(weight[i]);
}
//输出排序
System.out.println("输出序列");
double score = 0.0;
for(int i=1; i<=sumLabel; i++) {
int predict_r = 1;
for(int r=1;r<=(sumLabel+1); r++) {
//权重*特征向量-阈值
double sumWF=0;
for(int z=1; z<=136; z++) {
sumWF = sumWF + weight[z]*feature[i][z];
}
if(sumWF-b[r]<0) {
score = sumWF;
predict_r = r;
break;
}
}
System.out.println("predict="+predict_r+" score="+score);
}
}

package com.example.pointwise;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileWriter;
import java.io.InputStreamReader;
//参考 http://blog.csdn.net/pennyliang/article/details/17333373
public class prank {
//文件总行数(标记数)
private static int sumLabel;
//特征值 136个 (标号1-136)
private static double feature[][] = new double[100][138];
//特征值权重 136个 (标号1-136)
private static double weight [] = new double[138];
//相关度 其值有0-4五个级别 从1开始记录
private static int label [] = new int[100];
//查询id 从1开始记录
private static int qid [] = new int[100];
//定义阈值
private static double b[] = new double[100];
//读取文件
public static void readTxtFile(String filePath) {
try {
String encoding="GBK";
File file=new File(filePath);
if(file.isFile() && file.exists()) { //判断文件是否存在
InputStreamReader read = new InputStreamReader(new FileInputStream(file), encoding);
BufferedReader bufferedReader = new BufferedReader(read);
String lineTxt = null;
sumLabel =1; //初始化从1记录
//按行读取数据并分解数据
while((lineTxt = bufferedReader.readLine()) != null) {
System.out.println("行数 "+sumLabel);
String str = null;
int lengthLine = lineTxt.length();
//获取数据 字符串空格分隔
String arrays[] = lineTxt.split(" ");
for(int i=0; i<arrays.length; i++)
{
//获取每行样本的Label值
if(i==0) {
label[sumLabel] = Integer.parseInt(arrays[0]);
} else {
String subArrays[] = arrays[i].split(":"); //特征:特征值
if(i==1) { //获取qid
qid[sumLabel] = Integer.parseInt(subArrays[1]);
System.out.print(qid[sumLabel]+" ");
} else { //获取136维特征值
int number = Integer.parseInt(subArrays[0]); //判断特征
double value = Double.parseDouble(subArrays[1]);
feature[sumLabel][number] = value; //number数组标号:1-136
System.out.print(feature[sumLabel][number] +" ");
}
}
}
System.out.println(label[sumLabel]);
sumLabel++;
}
read.close();
} else {
System.out.println("找不到指定的文件\n");
}
} catch (Exception e) {
System.out.println("读取文件内容出错");
e.printStackTrace();
}
}
//写文件
public static void writeTxtFile(String filePath) {
try {
String encoding = "GBK";
FileWriter fileWriter = new FileWriter(filePath);
//按行写文件
for(int i=1; i<=sumLabel; i++) {
fileWriter.write("样本行数"+sumLabel+"\r\n");
fileWriter.flush();
//写数据
String value;
value = String.valueOf(label[i]);
fileWriter.write(value+" ");
value = String.valueOf(qid[i]);
fileWriter.write(value+" ");
//特征值 136
for(int j=1;j<=136;j++) {
value = String.valueOf(feature[i][j]);
fileWriter.write(value+" ");
}
fileWriter.write("\r\n");
}
fileWriter.close();
} catch(Exception e) {
System.out.println("写文件内容出错");
e.printStackTrace();
}
}
//学习排序
public static void learningToRank(String filePath){
//变量
double index [] = new double[100];
double tao [] = new double[100];
int realRank;
int predictRank;
//初始化
for(int i=0;i<138;i++) {
weight[i] = 0; //权重初值
}
//阈值初值
for(int i=0; i<=(sumLabel+1) ; i++) {
if(i==0) b[i] = -1;
else if(i==(sumLabel+1)) b[i] = 10000;
else b[i] = 0;
}
//计算权重 学习算法
for(int iter = 0; iter<100000; ++iter) //迭代1万次
{
for(int i=1; i<=sumLabel ; ++i) //总样本数
{
//测试顺序
predictRank = 1;
for(int r=1; r<=(sumLabel+1); ++r) {
//权重*特征向量-阈值
double sumWF = 0;
for(int z=1; z<=136; z++) {
sumWF = sumWF + weight[z]*feature[i][z];
}
if(sumWF-b[r]<0) {
predictRank = r;
break;
}
} //for r
realRank = label[i];
if(realRank!=predictRank) {
for(int r=1; r<=sumLabel; r++) {
if(realRank<=r)
{
index[r] = -1;
}
else
{
index[r] = 1;
}
}
double tao_sum = 0.0;
for(int r=1; r<=sumLabel; r++) {
//权重*特征向量-阈值
double sumWF = 0;
for(int z=1; z<=136; z++) {
sumWF = sumWF + weight[z]*feature[i][z];
}
if((sumWF - b[r]) * index[r] <= 0) {
tao[r] = index[r];
} else {
tao[r] = 0;
}
tao_sum += tao[r];
}
//权重赋值
for(int z=1; z<=136; z++) {
weight[z] = weight[z] + tao_sum*feature[i][z];
}
for(int r=1;r<=sumLabel;++r) {
b[r] = b[r] - tao[r];
}
}
} //sumLabel
} //迭代1万次
//输出权重
System.out.println("输出权重");
for(int i=1;i<=136;i++)
{
System.out.println(weight[i]);
}
//输出排序
System.out.println("输出序列");
double score = 0.0;
for(int i=1; i<=sumLabel; i++) {
int predict_r = 1;
for(int r=1;r<=(sumLabel+1); r++) {
//权重*特征向量-阈值
double sumWF=0;
for(int z=1; z<=136; z++) {
sumWF = sumWF + weight[z]*feature[i][z];
}
if(sumWF-b[r]<0) {
score = sumWF;
predict_r = r;
break;
}
}
System.out.println("predict="+predict_r+" score="+score);
}
}
//主函数
public static void main(String args[]) {
String fileInput = "train.txt";
String fileOutput = "output.txt";
String fileRank = "rank.txt";
//第一步 读取文件并解析数据
readTxtFile(fileInput);
//第二步 输出解析的基础数据
writeTxtFile(fileOutput);
//第三步 排序计算
learningToRank(fileRank);
}
}
