社区
Web 开发
帖子详情
POI解析Word2007转html时,转换后的表格内容编码乱了
xiaosimm
2015-01-27 09:49:26
如题,具体代码如下:
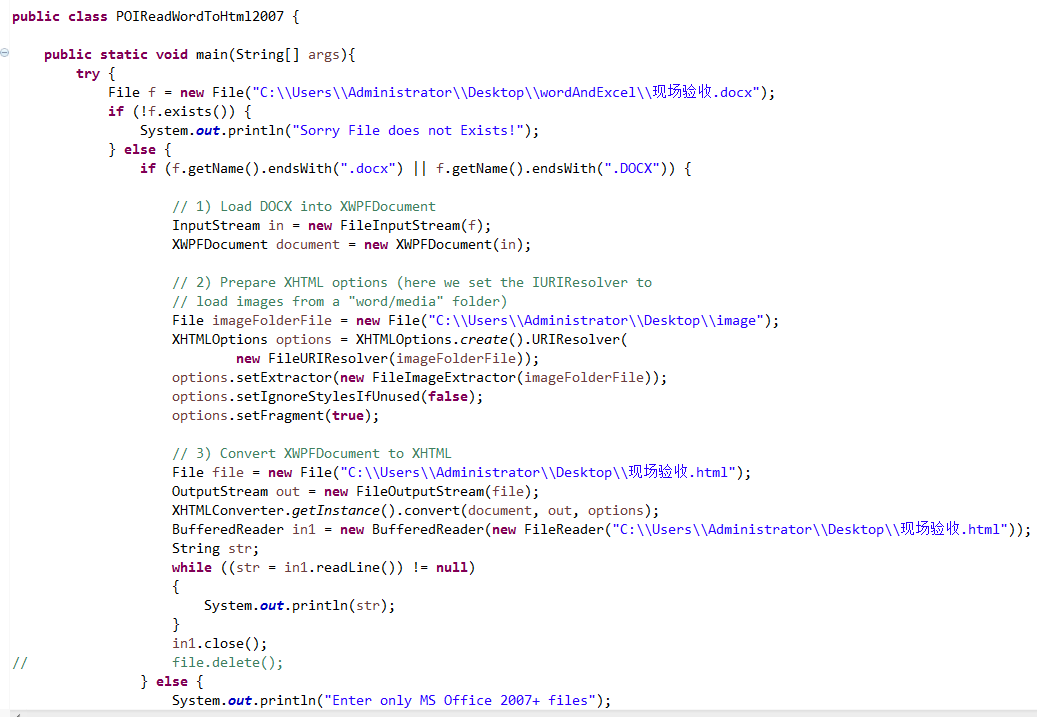
实现类的代码:
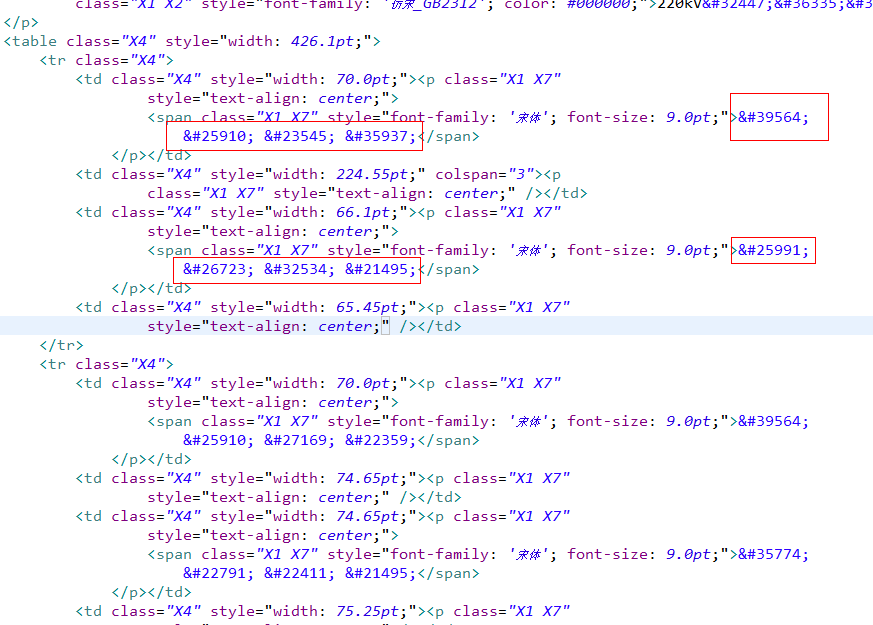
转换后的html代码:
这个编码是将ASCII 转成了 unicode编码,所以出现了这样的样子,大神些帮忙解决一下呢!小弟感激不尽!
...全文
586
4
打赏
收藏
POI解析Word2007转html时,转换后的表格内容编码乱了
如题,具体代码如下: 实现类的代码: 转换后的html代码: 这个编码是将ASCII 转成了 unicode编码,所以出现了这样的样子,大神些帮忙解决一下呢!小弟感激不尽!
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
4 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
珂学家 swallaws
2018-12-27
打赏
举报
回复
根据1楼(#1)和3楼的分析可以得到 1楼的做法正确但因为手动替换字符串显得代码不够简洁 3楼的做法会替换掉我不需要替换的东西,比如我的字符串输出时候要用到小于号(<)和大于号(>)的结合,3楼做法会替换回来导致html无法显示 所以我中和1楼和3楼的做法 String regExp = "&#\\d*;"; Matcher m = Pattern.compile(regExp).matcher("是的"); StringBuffer sb = new StringBuffer(); while (m.find()) { String s = m.group(0); s = StringEscapeUtils.unescapeHtml3(s); m.appendReplacement(sb,s); } m.appendTail(sb); return m.toString();
蓝鹰_李辉
2017-08-26
打赏
举报
回复
strHtml = StringEscapeUtils.unescapeHtml3(strHtml); 完美解决这个问题,其中strHtml 表示word转html后的 String 字符串
qq_24053795
2015-12-24
打赏
举报
回复
我也碰到过 解决方法 String regExp = "&#\\d*;"; Matcher m = Pattern.compile(regExp).matcher("是的"); StringBuffer sb = new StringBuffer(); while (m.find()) { String s = m.group(0); s = s.replaceAll("(&#)|;", ""); char c = (char) Integer.parseInt(s); m.appendReplacement(sb, Character.toString(c)); } m.appendTail(sb); return m.toString();
qq_24053795
2015-12-24
打赏
举报
回复
这是用java解决方式, js解决方法 var txt = '【题文】666666'; var divObj = document.createElement("div"); divObj.innerHTML = txt; alert(divObj.innerHTML);
word
文档
转
html
格式在线预览,使用了phpoffice,pydocx,java
POI
各方案,最终用unoconv解决
最近客户要做一个
word
,excel 文件在线预览功能,以下是实现此功能的全过程。 由于我们用的是PHP开发项目,最开始想到的是用PHPoffice里的php
word
来进行
转
换
,以下是关键代码。 <?php $php
Word
= \PhpOffice\Php
Word
\IOFactory::load('test.doc'); $xmlWriter = \PhpOffice\Php
Word
\IOFactory::createWriter($php
Word
, "
HTML
"); $xmlWriter->
poi
xlsx
转
换
html
,
word
文档
转
html
格式在线预览,使用了phpoffice,pydocx,java
POI
各方案,最终用unoconv解决...
最近客户要做一个
word
,excel 文件在线预览功能,以下是实现此功能的全过程。由于我们用的是PHP开发项目,最开始想到的是用PHPoffice里的php
word
来进行
转
换
,以下是关键代码。...
php 预览doc文件格式,
word
文档
转
html
格式在线预览,使用了phpoffice,pydocx,java
POI
各方案,最终用unoconv解决...
最近客户要做一个
word
,excel 文件在线预览功能,以下是实现此功能的全过程。由于我们用的是PHP开发项目,最开始想到的是用PHPoffice里的php
word
来进行
转
换
,以下是关键代码。$php
Word
= \PhpOffice\Php
Word
\IOFactory::load('test.doc');$xmlWriter = \PhpOffice\Php
Word
\IOFactory::cre...
HTML
表格
导出为Excel文件的实现方案
1、前端javascript可通过mime类型、blob对象或专业库(如sheetjs)实现
html
表格
导出excel,适用于中小型数据量;2、服务器端方案利用后端语言(如python的openpyxl、java的apache
poi
)处理复杂报表和大数据,确保安全性与格式控制;3、常见问题包括数据类型识别错误、样式丢失、大文件卡顿、浏览器兼容性及
乱
码,需通过设置单元格类型、使用后端样式api、分页处理、引入polyfill及指定
编码
解决。
Java实战:从
Word
模板填充到PDF生成与图片
转
换
全流程
解析
本文详细
解析
了使用Java实现从
Word
模板填充数据、生成PDF到
转
换
为图片的全流程。通过
poi
-tl、documents4j和PDFBox等核心库,提供了完整的代码示例和避坑指南,帮助开发者高效构建稳定、可扩展的文档处理服务,满足OA、合同生成等实际业务需求。
Web 开发
81,114
社区成员
341,727
社区内容
发帖
与我相关
我的任务
Web 开发
Java Web 开发
复制链接
扫一扫
分享
社区描述
Java Web 开发
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



