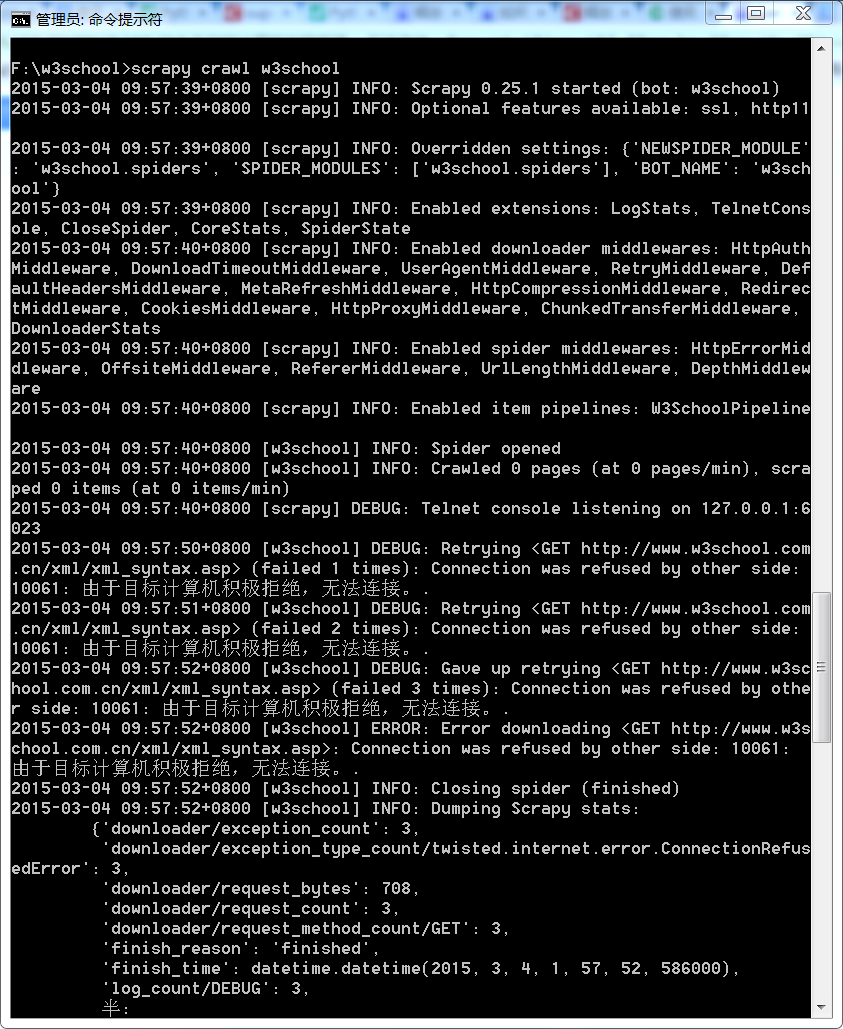
最近想要使用python的爬虫框架scrapy,在win7 64bit的电脑上安装之后,运行了该网站的例子【http://blog.csdn.net/u012150179/article/details/32911511】,出现了【DEBUG: Retrying <GET http://www.w3school.com.cn/xml/xml_syntax.asp> (failed 1 times): Connection was refused by other side: 10061: 由于目标计算机积极拒绝,无法连接。.】这个问题,截图如下,因为我刚开始接触这里不太懂怎么解决这个问题,在网上搜索也没有找到解决方案,请教各位,非常感谢!





 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
