手工方式运行 oracle的 LogMiner
先注册这两个SQL
Oracle_home/rdbms/admin/dbmslm.sql
Oracle_home/rdbms/admin/dbmslmd.sql
exec sys.dbms_logmnr.add_logfile(LogFileName => '/oracle/flash_recovery_area/orcl/archivelog/ARC0000115753_0829578749.0001',Options => dbms_logmnr.new);
exec sys.dbms_logmnr.start_logmnr(options=>sys.dbms_logmnr.DICT_FROM_ONLINE_CATALOG);
select seg_owner,count(*) from v$logmnr_contents group by seg_owner;
select count(1),substr(sql_redo,1,30) from v$logmnr_contents group by substr(sql_redo,1,30) order by count(1) desc;
--日志补全,不然redoSql出现 Unsupported SQLREDO
SELECT supplemental_log_data_min FROM v$database;
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
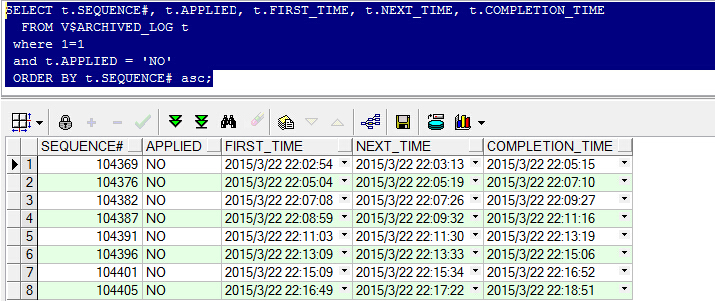
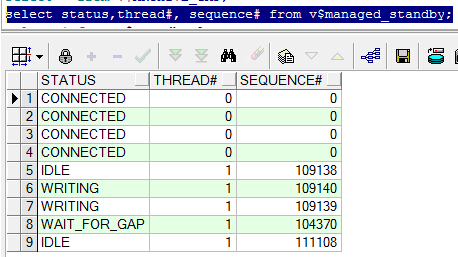
Media Recovery Waiting for thread 1 sequence 104370
Fetching gap sequence in thread 1, gap sequence 104370-104375
Tue Mar 24 10:47:12 2015
Archived Log entry 106125 added for thread 1 sequence 109135 rlc 829578749 ID 0x50e80b7b dest 2:
RFS[16]: Opened log for thread 1 sequence 109139 dbid 1357359483 branch 829578749
Tue Mar 24 10:47:16 2015
FAL[client]: Failed to request gap sequence
GAP - thread 1 sequence 104370-104375
DBID 1357359483 branch 829578749
FAL[client]: All defined FAL servers have been attempted.
-------------------------------------------------------------
Check that the CONTROL_FILE_RECORD_KEEP_TIME initialization
parameter is defined to a value that is sufficiently large
enough to maintain adequate log switch information to resolve
archivelog gaps.
alert.log出现很多这样的日志
备库 执行 select * from V$ARCHIVE_GAP; 却是空的


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享