社区
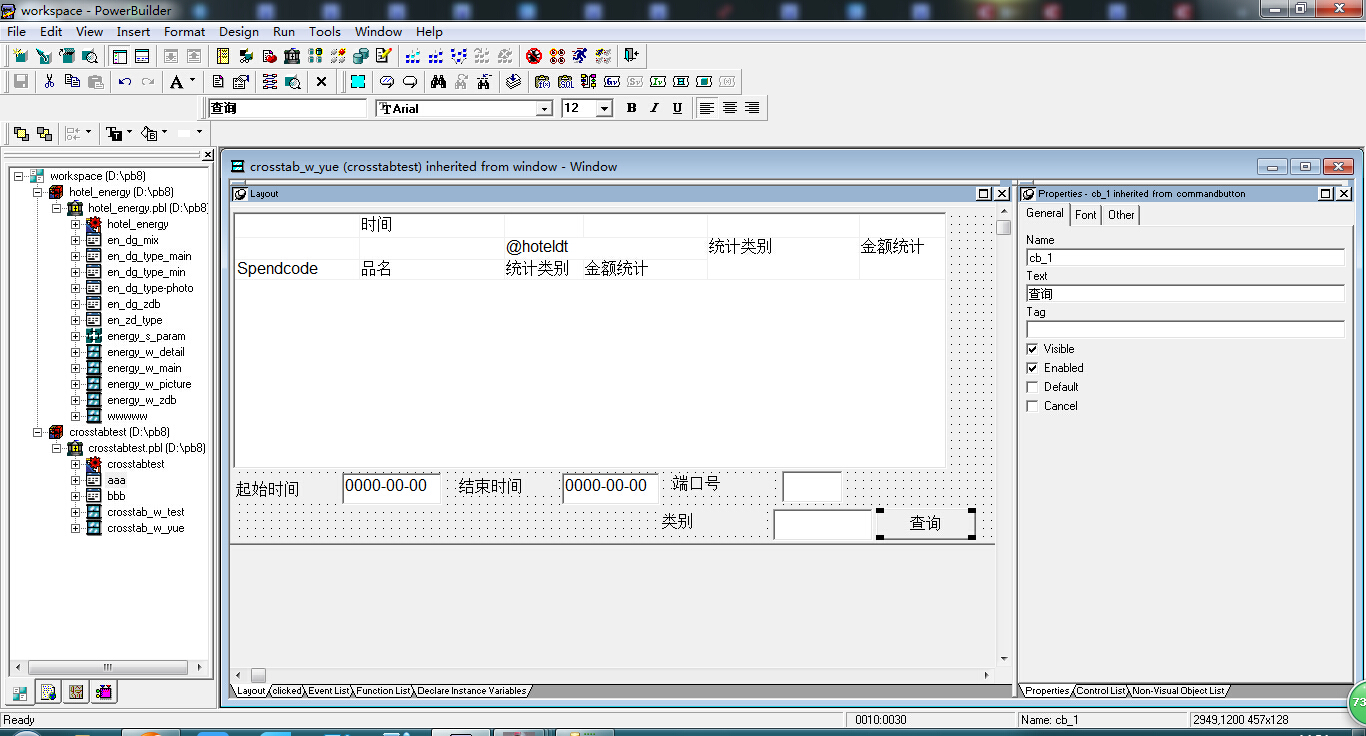
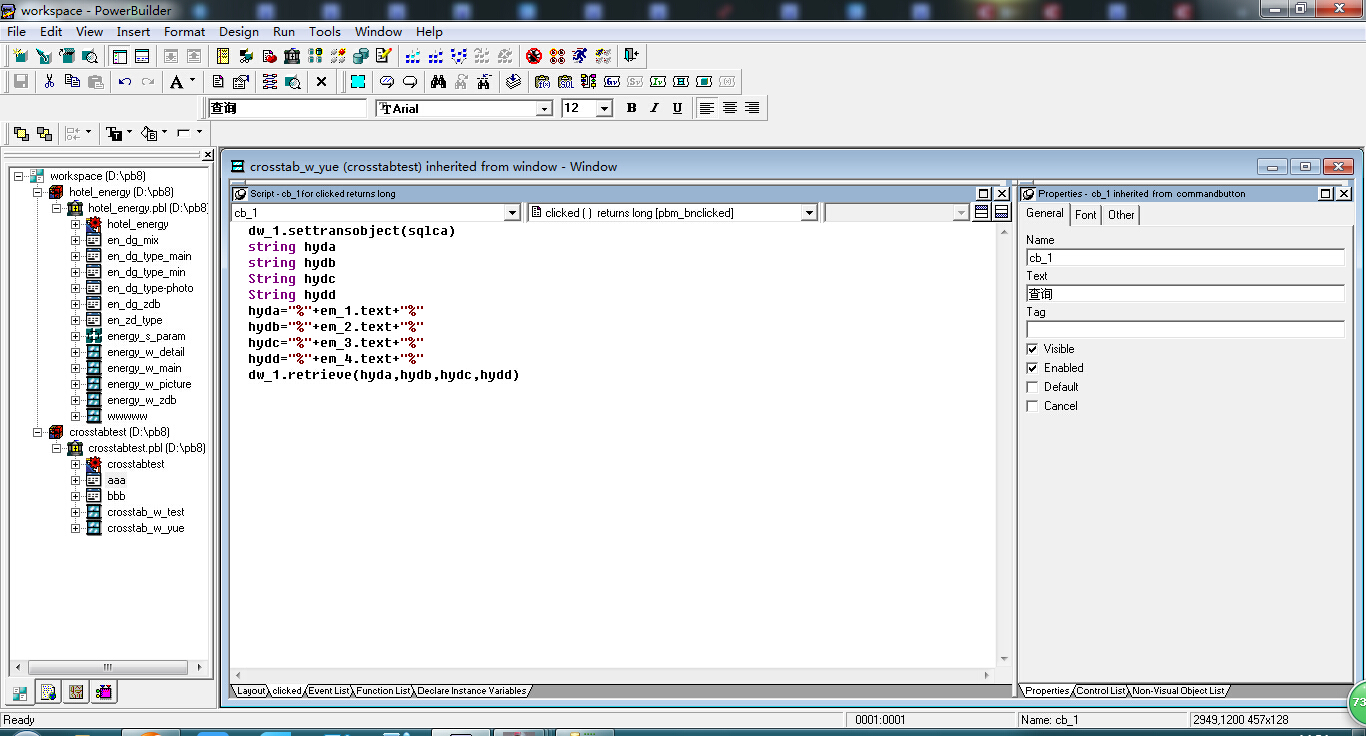
DataWindow
帖子详情
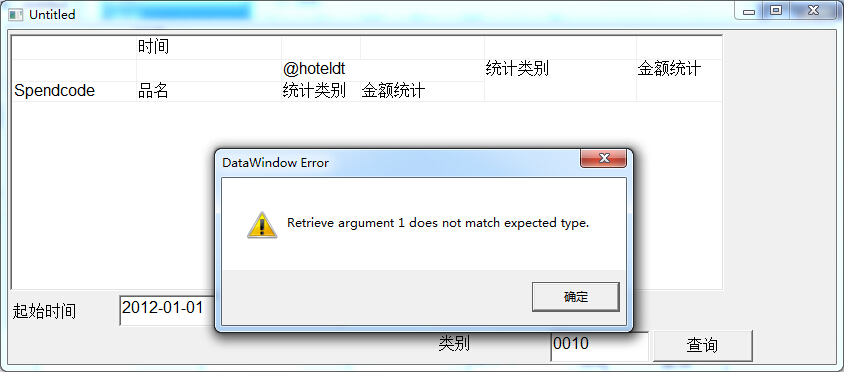
Retrieve argument 1 does not match expected type
bufenbaizhou
2015-04-01 02:57:33
在保存的click事件中 写入 最后提示
感谢解答 万谢万谢
...全文
706
1
打赏
收藏
Retrieve argument 1 does not match expected type
在保存的click事件中 写入 最后提示 感谢解答 万谢万谢
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
1 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
fengxiaohan211
2015-04-02
打赏
举报
回复
是模糊查询?应该是你的参数的检索类型不一致
Illegal
Argument
Exception Parameter value [4] did not
match
expected
type
[java.lang.String (na)]
问题: jpa 实现更新方法: 关键代码如下: @Query(value = " update Customer set custName = ?2 where custId = ?1") @Modifying public void updateCustomerById(String name,long id); 测试: @Test @Transactional @Rollback(value = false) public void tes
调试 Spring Data JPA 参数类型不匹配Parameter value [99] did not
match
expected
type
[java.lang.String (n/a)]
调整@Query注解,确保参数与方法签名匹配。如果如果endDate@Autowired类型一致性是关键实体类字段类型、方法参数类型和数据库列类型必须保持一致。使用Integer而不是String时,确保所有层级对齐。调试日志是利器Hibernate 的 SQL 日志和参数绑定信息能快速定位问题。启用和有助于分析。参数转换不可忽视BasePage到Pageable的转换是分页查询的核心,漏掉会导致运行时错误。自定义查询需谨慎使用@Query。
检索数据
检索数据 建表,插入数据: CREATE TABLE `sys_log` ( `id` int(64) NOT NULL COMMENT '编号', `
type
` char(1) DEFAULT '1' COMMENT '日志类型', `title` varchar(255) DEFAULT '' COMMENT '日志标题', `create_by` varchar(64) DE...
[WinXP故障]
解决WinXP系统启动慢的问题 症状:启动刚进入系统界面时,点什么都打不开,要等一分钟左右才能打开。 解决办法: 一、首先,请升级杀毒软件的病毒库,全面杀毒,以排除病毒原因。什么?你没安杀毒软件!?——除非你是老鸟(此文大虾和老鸟跳过^_^),否则建议安装。盗版的,不能升级!?这个问题别问偶,自己想办法! 二、开始→运行,输入msconfig→确定。在打开的系统系统
轻量级文档内自然语言检索器搭建指南
文档内检索是指在单个本地文件(如PDF、CSV、Word)中实现语义级内容查找的技术,其核心原理是将文本转化为向量表示,并通过余弦相似度匹配用户自然语言提问与文档片段的语义关联。相比传统关键词或正则匹配,它能跨越术语差异(如‘长江江豚’与‘Neophocaena asiaeorientalis’)、理解模糊表达(如‘最严重威胁’),显著提升科研与保护工作中对结构化/半结构化文档的交互效率。该技术具备低资源依赖、无需GPU、支持中文混合查询等工程优势,适用于濒危物种数据核查、政策文档速查、巡护日志分析等典型场
DataWindow
611
社区成员
20,469
社区内容
发帖
与我相关
我的任务
DataWindow
PowerBuilder DataWindow
复制链接
扫一扫
分享
社区描述
PowerBuilder DataWindow
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
