select count(1) as Counts from kjbg_ysdata t where ( contains(TITLE , 'the')>0 ) AND ( contains(SEARCHORG,'NASA (Unspecified Center)')>0 )
title,searchorg 都是建的全文索引 .
下面是时间和计划 。 .
...全文
10069打赏收藏
百万级数据count 很慢 .
select count(1) as Counts from kjbg_ysdata t where ( contains(TITLE , 'the')>0 ) AND ( contains(SEARCHORG,'NASA (Unspecified Center)')>0 ) title,searchorg 都是建的全文索引 . 下面是时间和计划 。 .
select count(1) as Counts from kjbg_ysdata t where ( contains(SEARCHORG,'NASA (Unspecified Center)')>0;
能跑多少秒?
顺便试一下:
exec ctx_ddl.sync_index('全文索引名');--同步索引,将新的数据同步到索引
exec ctx_ddl.optimize_index('全文索引名','FULL');--优化索引,清楚已删除的数据


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享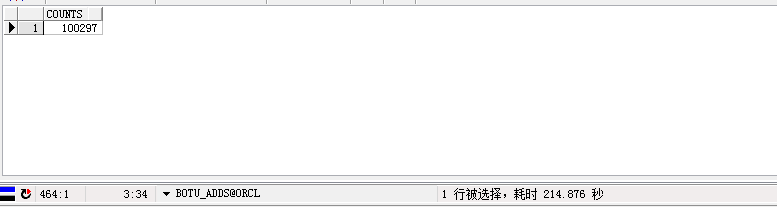 .
.




