环境:
centos6.6
jdk7
hadoop2.5.2
spark1.3.0
scala2.10.5
本地开发环境win7 eclipse4.4 jdk7
scala源码:
import org.apache.spark._
import SparkContext._
object App {
def main(args1: Array[String]) {
val greetStrings = new Array[String](3)
greetStrings.update(0, "spark://S1PA11:7077")
greetStrings.update(1, "hdfs://S1PA11:9000/tmp/input")
greetStrings.update(2, "file:///d:/outputxxxx/out7")
if (greetStrings.length != 3 ){
println("usage is org.test.WordCount ")
return
}
// val conf = new SparkConf();
val sc = new SparkContext(greetStrings(0), "WordCount",
System.getenv("SPARK_HOME"), Seq(System.getenv("SPARK_TEST_JAR")))
val textFile = sc.textFile(greetStrings(1))
println(textFile)
val result = textFile.flatMap(line => line.split("\\s+")).map(word => (word, 1)).reduceByKey(_ + _)
result.saveAsTextFile(greetStrings(2))
}
}
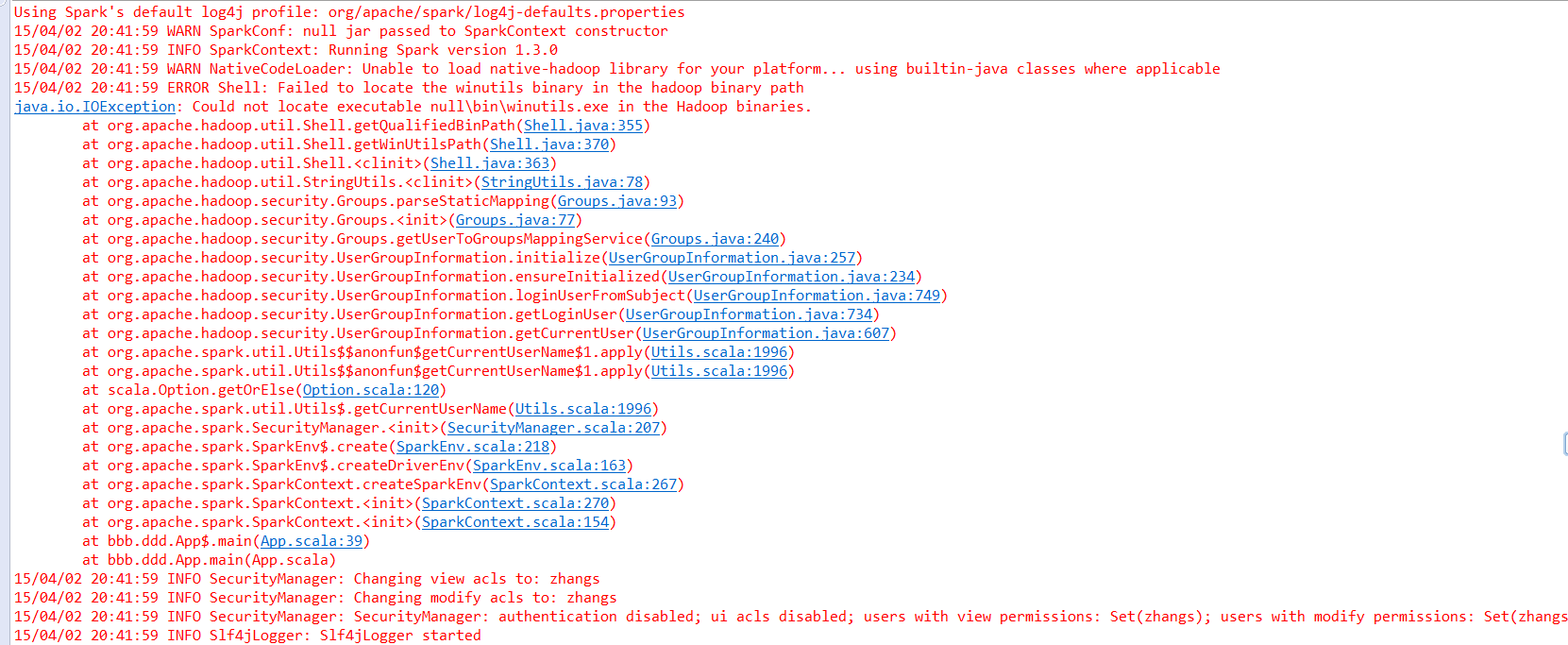
控制台输出:
15/04/02 20:42:00 INFO AppClient$ClientActor: Connecting to master akka.tcp://sparkMaster@S1PA11:7077/user/Master...
15/04/02 20:42:00 INFO SparkDeploySchedulerBackend: Connected to Spark cluster with app ID app-20150402204211-0009
15/04/02 20:42:00 INFO AppClient$ClientActor: Executor added: app-20150402204211-0009/0 on worker-20150402195450-S1PA222-58109 (S1PA222:58109) with 8 cores
15/04/02 20:42:00 INFO SparkDeploySchedulerBackend: Granted executor ID app-20150402204211-0009/0 on hostPort S1PA222:58109 with 8 cores, 512.0 MB RAM
15/04/02 20:42:00 INFO AppClient$ClientActor: Executor added: app-20150402204211-0009/1 on worker-20150402195451-S1PA11-55211 (S1PA11:55211) with 8 cores
15/04/02 20:42:00 INFO SparkDeploySchedulerBackend: Granted executor ID app-20150402204211-0009/1 on hostPort S1PA11:55211 with 8 cores, 512.0 MB RAM
15/04/02 20:42:00 INFO AppClient$ClientActor: Executor updated: app-20150402204211-0009/0 is now LOADING
15/04/02 20:42:00 INFO AppClient$ClientActor: Executor updated: app-20150402204211-0009/1 is now LOADING
15/04/02 20:42:00 INFO AppClient$ClientActor: Executor updated: app-20150402204211-0009/0 is now RUNNING
15/04/02 20:42:00 INFO AppClient$ClientActor: Executor updated: app-20150402204211-0009/1 is now RUNNING
15/04/02 20:42:00 INFO PlatformDependent: Your platform does not provide complete low-level API for accessing direct buffers reliably. Unless explicitly requested, heap buffer will always be preferred to avoid potential system unstability.
15/04/02 20:42:00 INFO NettyBlockTransferService: Server created on 16378
15/04/02 20:42:00 INFO BlockManagerMaster: Trying to register BlockManager
15/04/02 20:42:00 INFO BlockManagerMasterActor: Registering block manager zhangsheng:16378 with 950.4 MB RAM, BlockManagerId(<driver>, zhangsheng, 16378)
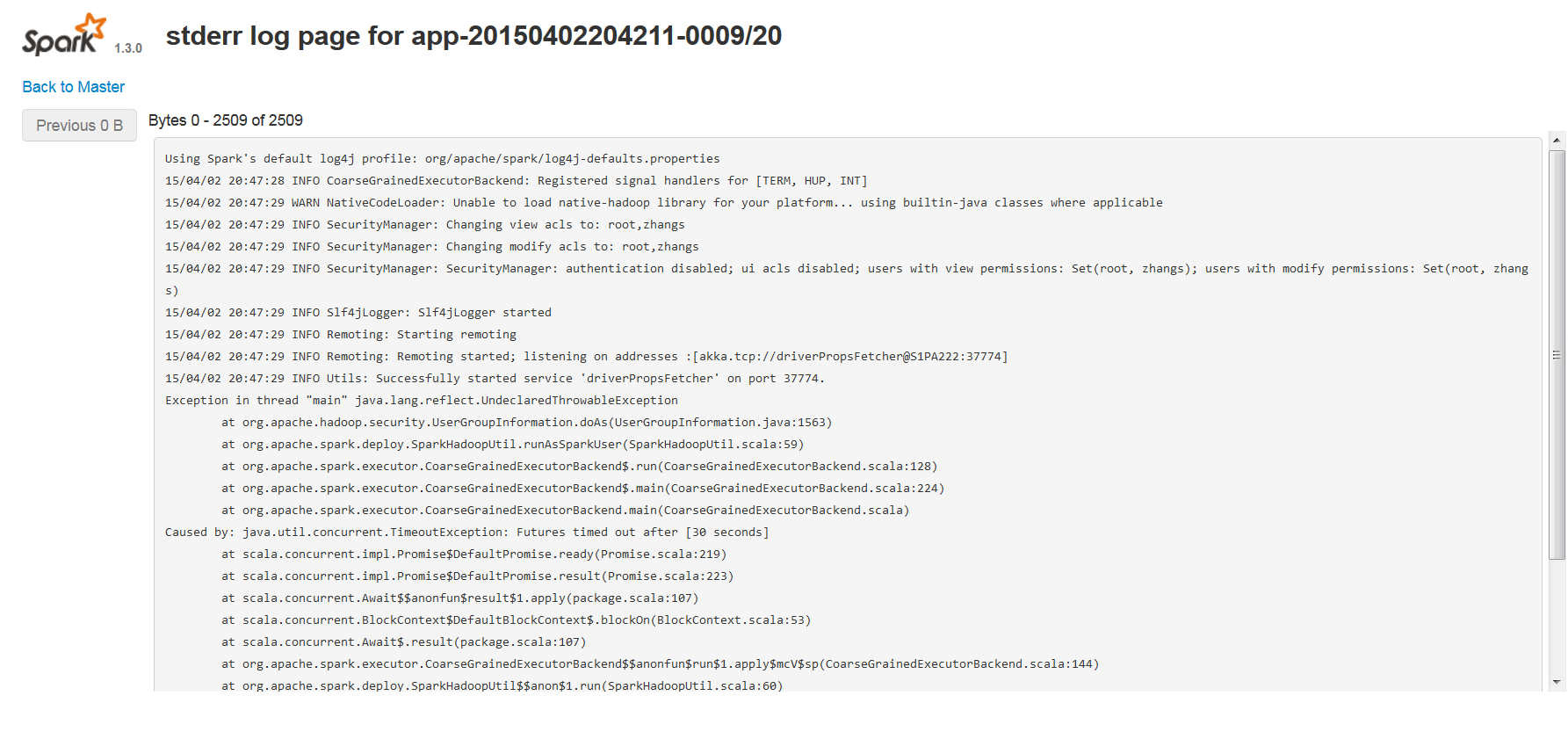
查看spark worker日志:
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/04/02 19:18:12 INFO CoarseGrainedExecutorBackend: Registered signal handlers for [TERM, HUP, INT]
15/04/02 19:18:12 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/04/02 19:18:12 INFO SecurityManager: Changing view acls to: root,zhangs
15/04/02 19:18:12 INFO SecurityManager: Changing modify acls to: root,zhangs
15/04/02 19:18:12 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root, zhangs); users with modify permissions: Set(root, zhangs)
15/04/02 19:18:12 INFO Slf4jLogger: Slf4jLogger started
15/04/02 19:18:12 INFO Remoting: Starting remoting
15/04/02 19:18:13 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://driverPropsFetcher@S1PA222:56756]
15/04/02 19:18:13 INFO Utils: Successfully started service 'driverPropsFetcher' on port 56756.
Exception in thread "main" java.lang.reflect.UndeclaredThrowableException
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1563)
at org.apache.spark.deploy.SparkHadoopUtil.runAsSparkUser(SparkHadoopUtil.scala:59)
at org.apache.spark.executor.CoarseGrainedExecutorBackend$.run(CoarseGrainedExecutorBackend.scala:128)
at org.apache.spark.executor.CoarseGrainedExecutorBackend$.main(CoarseGrainedExecutorBackend.scala:224)
at org.apache.spark.executor.CoarseGrainedExecutorBackend.main(CoarseGrainedExecutorBackend.scala)
Caused by: java.util.concurrent.TimeoutException: Futures timed out after [30 seconds]
at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:219)
at scala.concurrent.impl.Promise$DefaultPromise.result(Promise.scala:223)
at scala.concurrent.Await$$anonfun$result$1.apply(package.scala:107)
at scala.concurrent.BlockContext$DefaultBlockContext$.blockOn(BlockContext.scala:53)
at scala.concurrent.Await$.result(package.scala:107)
at org.apache.spark.executor.CoarseGrainedExecutorBackend$$anonfun$run$1.apply$mcV$sp(CoarseGrainedExecutorBackend.scala:144)
at org.apache.spark.deploy.SparkHadoopUtil$$anon$1.run(SparkHadoopUtil.scala:60)
at org.apache.spark.deploy.SparkHadoopUtil$$anon$1.run(SparkHadoopUtil.scala:59)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1548)
... 4 more


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享