社区
Java
帖子详情
怎么用java写网络爬虫将网页中的指定数据下载到本地excel文档中
sunshinewxz
2015-04-11 06:27:56
刚开始学网络爬虫,只会把相关的数据打印出来,但是不知道怎么才能下载到本地的文档中,并且如果那个数据是动态的又该怎么办呢?求各位大神详细的java代码
...全文
335
3
打赏
收藏
怎么用java写网络爬虫将网页中的指定数据下载到本地excel文档中
刚开始学网络爬虫,只会把相关的数据打印出来,但是不知道怎么才能下载到本地的文档中,并且如果那个数据是动态的又该怎么办呢?求各位大神详细的java代码
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
3 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
午阿哥
2016-07-12
打赏
举报
回复
午阿哥
2016-07-12
打赏
举报
回复
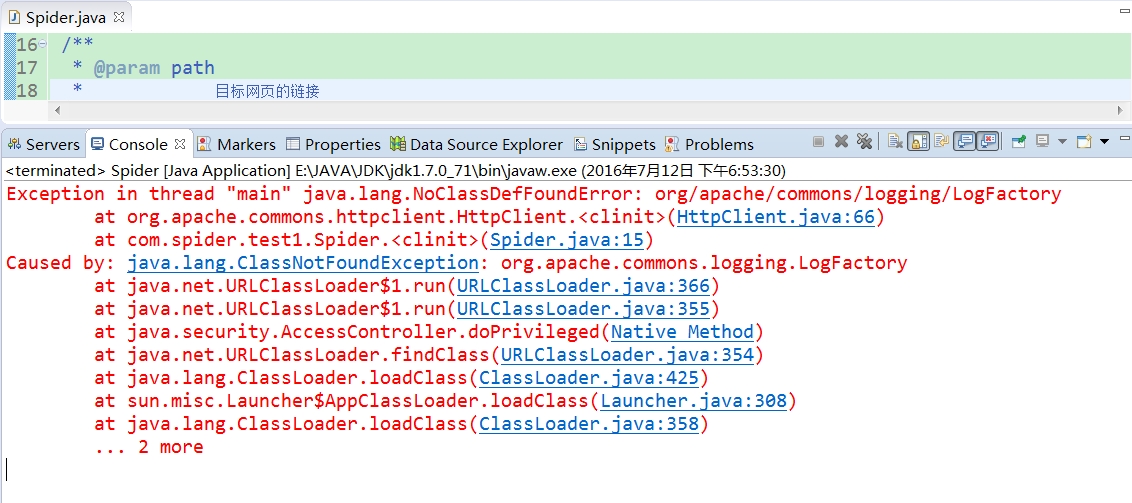
我刚开始学习写爬虫,代码跑起来,是异常,帮我看看; import java.io.FileOutputStream; import java.io.InputStream; import java.io.OutputStream; import org.apache.commons.httpclient.HttpClient; import org.apache.commons.httpclient.HttpStatus; import org.apache.commons.httpclient.methods.GetMethod; /** * * @author CallMeWhy * */ public class Spider { private static HttpClient httpClient = new HttpClient(); /** * @param path * 目标网页的链接 * @return 返回布尔值,表示是否正常下载目标页面 * @throws Exception * 读取网页流或写入本地文件流的IO异常 */ public static boolean downloadPage(String path) throws Exception { // 定义输入输出流 InputStream input = null; OutputStream output = null; // 得到 post 方法 GetMethod getMethod = new GetMethod(path); // 执行,返回状态码 int statusCode = httpClient.executeMethod(getMethod); // 针对状态码进行处理 // 简单起见,只处理返回值为 200 的状态码 if (statusCode == HttpStatus.SC_OK) { input = getMethod.getResponseBodyAsStream(); // 通过对URL的得到文件名 String filename = path.substring(path.lastIndexOf('/') + 1) + ".html"; // 获得文件输出流 output = new FileOutputStream(filename); // 输出到文件 int tempByte = -1; while ((tempByte = input.read()) > 0) { output.write(tempByte); } // 关闭输入流 if (input != null) { input.close(); } // 关闭输出流 if (output != null) { output.close(); } return true; } return false; } public static void main(String[] args) { try { // 抓取百度首页,输出 Spider.downloadPage("http://www.baidu.com"); } catch (Exception e) { e.printStackTrace(); } } }
marzone
2016-04-06
打赏
举报
回复
问题解决没?我也在学习!
爬虫
网页
的
数据
java
_怎么用
java
写
网络
爬虫
将
网页
中
的
指定
数据
下载
到本地
excel
文档
中
...
本文介绍如何使用
Java
的 HttpURLConnection 类实现 HTTP POST 请求,并展示如何读取服务器响应的
数据
。
常用的
网络
爬虫
工具推荐
本文精选了十款
网络
爬虫
工具,包括八爪鱼、火车头、集搜客GooSeeker等,覆盖免费与付费、开源与闭源选项,适用于不同场景的
数据
采集需求,如批量抓取、智能分析及云采集。
【推荐收藏】33款可用来抓
数据
的开源
爬虫
软件工具
在大
数据
时代,
网络
爬虫
是
数据
采集的重要工具。本文介绍33款优秀开源
爬虫
软件,涵盖
Java
、Python、C++、C#、PHP等语言实现。还提及
爬虫
技术概述,包括传统
爬虫
和聚焦
爬虫
工作流程,最后推荐了Sniff Master抓包工具,并提醒选工具要考虑多因素。
Java
网络
爬虫
本文详细介绍了
网络
爬虫
的基本概念、工作原理及其实现流程,包括从种子链接出发进行图遍历,采用宽度优先搜索策略,以及具体的代码实现步骤。通过宽度优先搜索,
爬虫
能高效地抓取
网络
中
的相关
网页
,并对
网页
内容进行
下载
和解析。
用python抓取一个
网页
的xhr,python爬取网站
数据
代码
本文是Python
网页
抓取教程,介绍了使用Python抓取
网页
数据
并
写
入
Excel
的方法。先讲解了Python用于
网页
抓取的优势,介绍了Requests、Beautiful Soup等相关库,接着分步骤说明了构建
网络
爬虫
的过程,包括环境准备、
数据
提取、导出等,最后给出了更多
网络
抓取的附加功能建议。
Java
51,408
社区成员
86,093
社区内容
发帖
与我相关
我的任务
Java
Java相关技术讨论
复制链接
扫一扫
分享
社区描述
Java相关技术讨论
java
spring boot
spring cloud
技术论坛(原bbs)
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享