社区
CUDA高性能计算讨论
帖子详情
关于Cuda优化寄存器问题
杨阿毛阿
2015-04-11 07:34:37
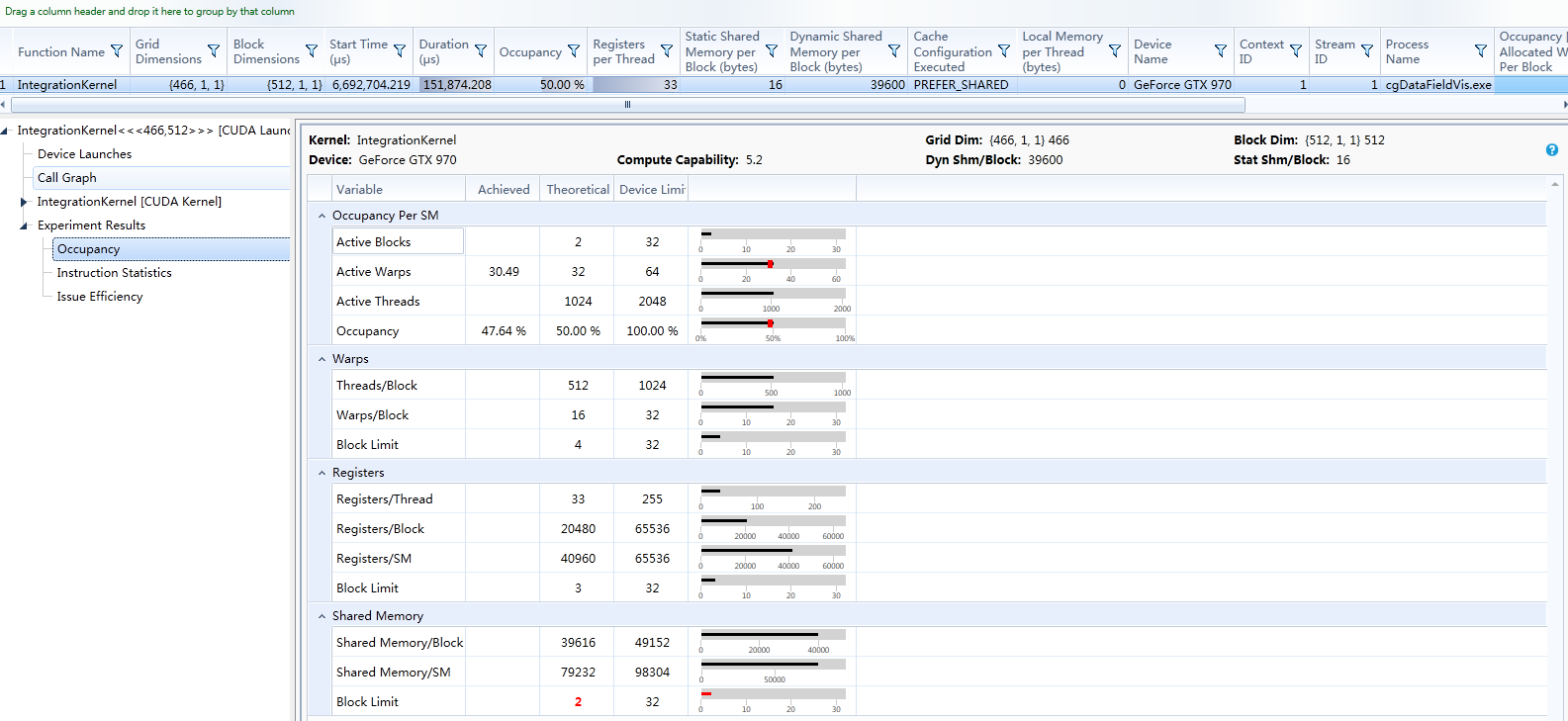
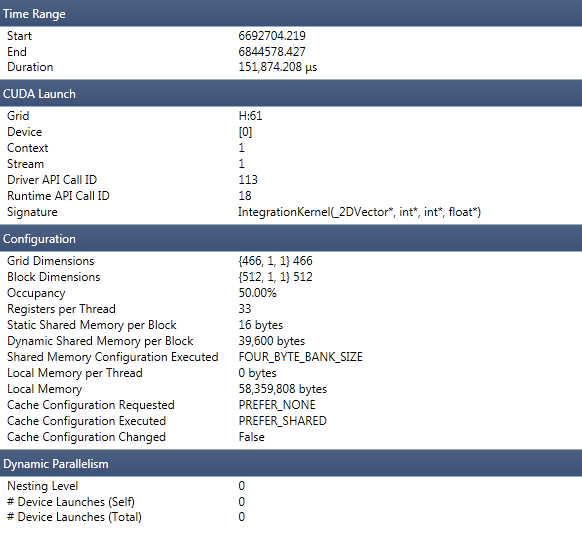
上图为本人程序Nsight分析结果,由于寄存器个数为33,始终找不到方法将寄存器的个数降到32,已将程序中使用的中间变量全部替换,请各位大神帮忙,通过分析此程序,给予优化建议。尤其是,如何降低寄存器的使用个数。
上图显示Local memory per thread 的使用量为0,所以,我想可否将寄存器转换到LOCAL MEMEORY?已降低寄存器数量?谢谢~~
...全文
343
1
打赏
收藏
关于Cuda优化寄存器问题
上图为本人程序Nsight分析结果,由于寄存器个数为33,始终找不到方法将寄存器的个数降到32,已将程序中使用的中间变量全部替换,请各位大神帮忙,通过分析此程序,给予优化建议。尤其是,如何降低寄存器的使用个数。 上图显示Local memory per thread 的使用量为0,所以,我想可否将寄存器转换到LOCAL MEMEORY?已降低寄存器数量?谢谢~~
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
1 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
baodijun
2015-10-23
打赏
举报
回复
如果寄存器使用确实成为程序瓶颈。以下策略可以减少程序中寄存器的使用。 1、 拆分代码为较小的Kernel(一般需要同时修改算法才能达到比较好的效果)。 2、 运用maxrregcount编译选项控制寄存器使用。
GPU编程之进击的
优化
-李修宇.docx
第一章 设备微架构 1.0
CUDA
设备 1.0.0 核心微架构 1.0.1 指令编码格式 1.0.2
寄存器
文件结构 1.0.3 指令流水线 1.0.4 Pascal架构(待续) 1.1 GCN设备 1.1.0 核心微架构 1.1.1 指令编码格式 1.1.2
寄存器
文件结构 1.1.3 指令流水线 1.2 GPU设备上的条件分支 第二章 GPU矩阵乘法的高效实现 2.0 前言 2.1 指令级并行和数据预取 2.2 双缓冲区 2.3 宽数据内存事务 2.4 二级数据预取 2.5 细节调优 第三章 基于GPU的大规模稀疏矩阵直接求解器 3.0 简介 3.1 基于quotient graph的符号分析 3.1.1 顶点重排序 3.1.2 构建消去树 3.1.3 寻找超结点 3.1.4 符号分解 3.2 多波前法 3.3 超节点方法 3.4 多波前+超节点方法的并行分解算法 小结 参考资料 第四章 CNN中的卷积计算 前言 1 基于矩阵乘法的卷积算法 2 类矩阵乘法的卷积算法 小结 第五章 基于GPU的LU分解(待续) 5.0 一般实现 5.1 分块实现 5.2 使用动态并行 5.3 多GPU版本 第六章 GPU上的光线追踪(待续) 6.1 kd-tree算法介绍及内核实现 6.2 less-分支版本的kd-tree算法及内核实现 6.3 ropes-kdtree算法及内核实现 第七章 LBM流体计算(待续) 尾章 GPU编程
优化
技术总结 4.1.0
CUDA
设备上的
优化
技术 4.1.1 访存
优化
4.1.2 指令
优化
4.1.3 内核调用
优化
4.2.0 GCN设备上的
优化
技术 4.2.1 访存
优化
4.2.2 指令
优化
4.2.3 内核调用
优化
4.3 构建性能可移植的程序
dopt:D的数值
优化
和深度学习框架
点 D的数值
优化
和深度学习框架。 当前功能包括: 能够构造张量值函数的符号表示 基本的算术和数学运算(add,sub,mul,div,abs,log,exp,...) 基本矩阵运算(乘法,转置) 反向模式自动微分 神经网络原语 神经网络构建实用程序 几种预建模型(VGG,Wide ResNet) 用于添加第三方操作及其衍生物的框架,以及用于CPU和
CUDA
后端的功能
寄存器
实现 在线
优化
算法:SGD,ADAM,AMSGrad等更多功能! 该项目仍处于初期阶段,有些事情可能无法正常进行。 未来计划的一些功能包括: 向CPU和
CUDA
后端添加
优化
的能力 更多用于训练深度网络的实用程序(数据加载器,标准训练循环等) 文件 文档可以在找到。 提供有关如何使用此框架进行深度学习的简要概述。 使用 使用dopt的最简单方法是将其作为依赖项添加到项目的dub配置文件中。 有关如何执行此操作
FFmpeg系列之35:FFmpeg+
CUDA
硬件加速原理与案例
FFmpeg+
CUDA
硬件加速原理与案例实战 FFmpeg系列之35FFmpeg第2季编解码专题之5:FFmpeg+
CUDA
硬件加速原理与案例实战本课程主要讲解的知识点包括:GPU高性能编程
CUDA
入门、
CUDA
编程模型的原理解析、
CUDA
编程小白案例...
基于图形处理器的球面Voronoi图生成算法
优化
(2015年)
基于四元三角格网(QTM)之间距离计算与比较的球面Voronoi图生成算法相对于扩张算法具有较高的精度,但由于需要计算并比较每个格网到所有种子点的距离,致使算法效率较低。针对这一
问题
,利用图形处理器(GPU)并行计算对算法进行实现,然后从GPU共享内存、常量内存、
寄存器
等三种内存的访问方面进行
优化
,最后用C++语言和统一计算设备架构(
CUDA
)开发了实验系统,对
优化
前后算法的效率进行对比。实验结果表明,不同内存的合理使用能在很大程度上提高算法的效率,且数据规模越大,所获得的加速比越高。
matlab代码影响-PseudoCTImaging:基于基于图集(基于贴片)的方法从MRI输入图像中合成CT图像
matlab代码影响伪CTImaging 基于多图集并在mutlicore和manycore平台上进行补丁的基于伪CT的伪CT估计(请参见[1,2])。 CT采集模式可提供获得PET衰减图所需的电子密度。 当考虑到PET / MR多模态时,从MRI图像合成伪CT图像是纠正PET的自然解决方案。 基本思想如下:1)给定输入的MRI图像生成伪CT; 2)根据伪CT体积计算衰减图; 3)应用衰减图校正PET图像。 我们将专注于生成伪CT图像的第一步:合成。 该算法已使用以下方法实现: 单核英特尔ICC 多核OpenMP 具有三项
优化
的GPU(
CUDA
) 通用汽车全球记忆 GM2全局存储器,
寄存器
改进 SM共享内存 Matlab函数读取输入MRI的数据,解剖图谱并将分割结果写入Matlab文件.mat中。 有一种方法可以随机创建数据以进行测试。 将来,我将使用MatrixIO扩展读取数据。 为方便起见,我仅在一类中实现了该算法,以方便在服务器中进行部署(编译和执行)。 将来,我将改善模块化,并创建一个用于使用UI的dll。 下图示意性地说明了我们建议的工作流程。 输入参数是表示要从中进行模态的
CUDA高性能计算讨论
353
社区成员
615
社区内容
发帖
与我相关
我的任务
CUDA高性能计算讨论
CUDA高性能计算讨论
复制链接
扫一扫
分享
社区描述
CUDA高性能计算讨论
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
