社区
Hadoop生态社区
帖子详情
运行hadoop的MapReduce示例,在running job卡住,不能继续运行
chelseayuan21
2015-05-09 04:39:07
求大神解答!!在网上搜索解决办法,都没搜到答案
我的hadoop版本是CDH5.4的,安装了伪分布模式,想运行示例程序验证一下,结果就卡在running job上,没法继续运行
运行示例如下:
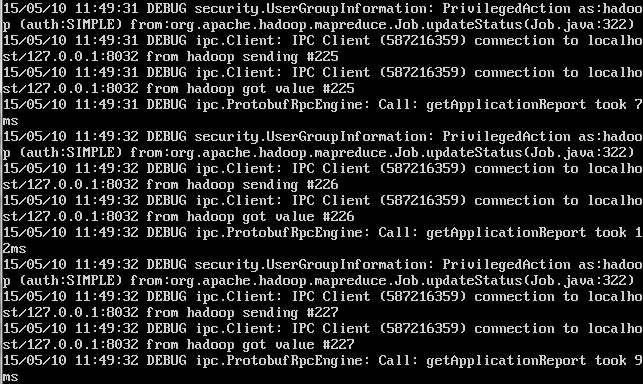
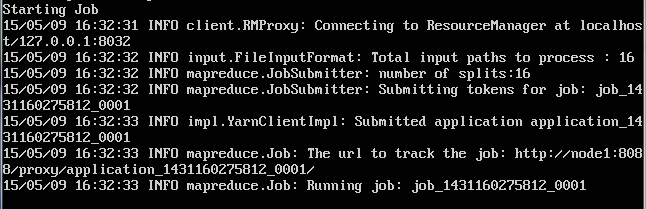
结果在running job上卡住了
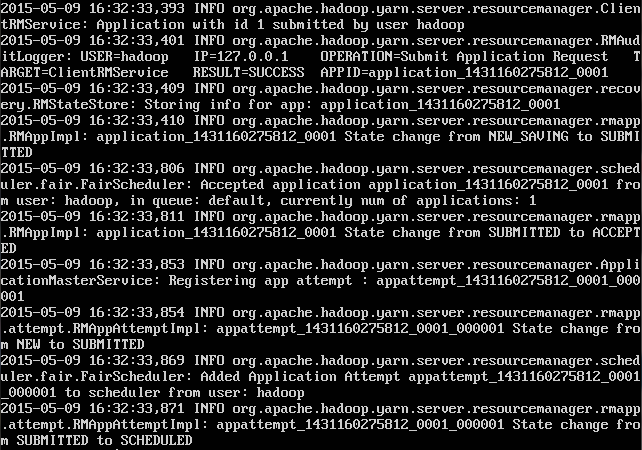
查看resourcesmanager的日志,提示到了"State change from SUBMITTED to SCHEDULED"就没有了:
求大神指导阿!!要崩溃了……
...全文
7485
11
打赏
收藏
运行hadoop的MapReduce示例,在running job卡住,不能继续运行
求大神解答!!在网上搜索解决办法,都没搜到答案 我的hadoop版本是CDH5.4的,安装了伪分布模式,想运行示例程序验证一下,结果就卡在running job上,没法继续运行 运行示例如下: 结果在running job上卡住了 查看resourcesmanager的日志,提示到了"State change from SUBMITTED to SCHEDULED"就没有了: 求大神指导阿!!要崩溃了……
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
11 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
清风半夜鸣蝉
2017-11-15
打赏
举报
回复
最烦这种不负责任的人,解决问题了不贴出来分享
wisdomB
2016-08-11
打赏
举报
回复
请问,楼主是怎么解决的呢?我现在也遇到这种情况,一执行mapreduce程序就卡了,然后直接注销了。
ssdmg521
2016-07-04
打赏
举报
回复
咋解决的,发下啊
fullmooneur
2016-06-14
打赏
举报
回复
1
和楼主遇到的是一样的问题,我的DEBUG消息和你的相同,hosts设置没有问题,而且很诡异的是,我之前跑任务是没有问题的,可是突然之间就不行了,回忆了一下也没有更改配置,想问一下楼主是怎么解决问题的,谢谢
sinat_26742267
2016-03-25
打赏
举报
回复
怎么解决的?楼主
qq_32561475
2015-11-04
打赏
举报
回复
我也是这个问题,大家是怎么解决的??求解答
小哥莫骚
2015-11-01
打赏
举报
回复
楼主,你是怎么解决的啊?小弟我也遇到这个问题,快搞疯我了。。。
chelseayuan21
2015-05-10
打赏
举报
回复
引用 1 楼 Vigiles 的回复:
修改日志级别
export HADOOP_ROOT_LOGGER=DEBUG,console
查看下详细信息
请问这个是什么问题?
chelseayuan21
2015-05-10
打赏
举报
回复
引用 1 楼 Vigiles 的回复:
修改日志级别 export HADOOP_ROOT_LOGGER=DEBUG,console 查看下详细信息
谢谢啊,终于解决问题了!hosts设置不正确导致的!
vigiles
2015-05-09
打赏
举报
回复
修改日志级别 export HADOOP_ROOT_LOGGER=DEBUG,console 查看下详细信息
Hadoop
MapReduce
入门
本文作为
Hadoop
MapReduce
的入门篇,首先对
MapReduce
原理进行简单介绍,然后以一个简单的例子说明如何编写一个简单的MapReuce程序。
18、
MapReduce
的计数器与通过
MapReduce
读取-写入数据库
示例
18、
MapReduce
的计数器与通过
MapReduce
读取_写入数据库
示例
网址:https://blog.csdn.net/chenwewi520feng/article/details/130454774 本文介绍
MapReduce
的计数器使用以及自定义计数器、通过
MapReduce
读取与写入数据库
示例
。 本文的前提依赖是
hadoop
可正常使用、mysql数据库中的表可用且有数据。 本文分为2个部分,即计数器与读写mysql数据库。
MapReduce
计数器及其通过
MapReduce
实现数据库读写
示例
打开下面链接,直接免费下载资源: https://renmaiwang.cn/s/qaiji 18、
MapReduce
的计数器与通过
MapReduce
读取_写入数据库
示例
网址: input files to process”表示处理的总输入文件数量,“number of splits”指示文件被分割成多少个块进行处理,“
Running
job
”显示作业的状态等。自定义计数器则是开发者根据实际需求创建的,用于跟踪特定任务的特定指标。开发者可以在Mapper或Reducer类中增加自定义计数器,然后在代码中增加计数器的值。这样,当作业完成后,可以通过查看计数器的值来分析程序的行为和性能。接下来,我们将讨论如何通过
MapReduce
与数据库交互,尤其是MySQL数据库。在大数据场景下,有时需要将
MapReduce
处理的结果存储到关系型数据库中,或者从数据库中读取数据进行处理。
Hadoop
提供了JDBC(Java Database Connectivity)接口,使得
MapReduce
作业能够与数据库进行连接和操作。要实现
MapReduce
读取数据库,首先需要在Mapper类中加载数据库驱动并建立连接。然后,可以在map()方法中使用SQL查询获取所需数据。在Reduce阶段,可以对数据进行进一步处理和聚合,最后将结果写入到数据库中。对于写入数据库,通常在Reducer类的reduce()方法或cleanup()方法中进行,将处理后的数据转换为适合数据库存储的格式,然后通过JDBC API执行插入、更新或删除等操作。需要注意的是,由于
MapReduce
作业可能涉及大量的数据写入,因此需要考虑数据库的并发处理能力和性能优化策略。总结一下,
MapReduce
的计数器提供了强大的监控和调试能力,而通过
MapReduce
与数据库的交互则扩展了大数据处理的应用场景。开发者可以根据需求利用计数
apache hbase reference guide
apache hbase reference guide
Hadoop生态社区
20,844
社区成员
4,695
社区内容
发帖
与我相关
我的任务
Hadoop生态社区
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
复制链接
扫一扫
分享
社区描述
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章
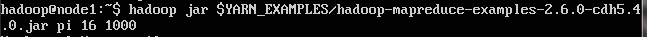


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享