579
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享#include <stdio.h>
#include "time.h"
#include <windows.h>
#include <cuda_runtime.h>
#define SIZE_Y 256
#define SIZE_X 256
#define BLOCK_NUM 2
#define THREAD_NUM 512
#define SIZE_Y_T 8
#define SIZE_X_T 8
bool InitCUDA()
{
int count;
cudaGetDeviceCount(&count);
if(count == 0) {
fprintf(stderr, "There is no device.\n");
return false;
}
int i;
for(i=0; i< count; i++) {
cudaDeviceProp prop;
if(cudaGetDeviceProperties(&prop, i) == cudaSuccess) {
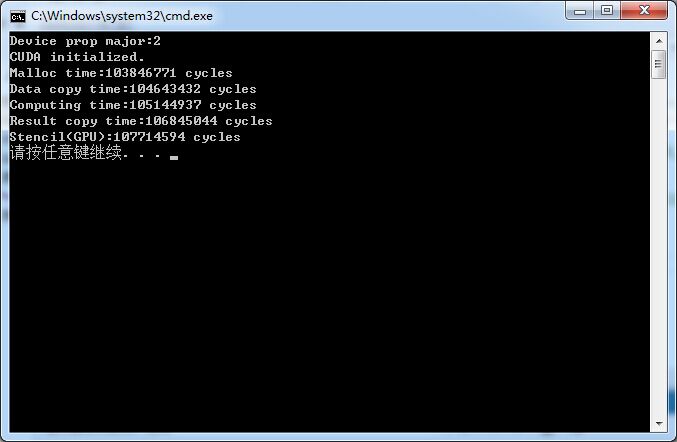
fprintf(stderr, "Device prop major:%d\n", prop.major);
if(prop.major >= 1) {
break;
}
}
}
if(i == count) {
fprintf(stderr, "There is no device supporting CUDA.\n");
return false;
}
cudaSetDevice(i);
return true;
}
inline unsigned __int64 GetCycleCount()
{
__asm _emit 0x0F
__asm _emit 0x31
}
__global__ static void stencil(int *num, int* result)
{
int sum = 0;
const int tid = threadIdx.x;
const int bid = blockIdx.x;
for(int j=1; j< SIZE_Y_T-1; j++) {
for(int i=1; i< SIZE_X_T-1; i++) {
//result[(j+tid/32*32)*1024+i+tid%32*32] = 0.5*num[(j+tid/32*32)*1024+i+tid%32*32]+0.125*(num[(j+tid/32*32)*1024+i+tid%32*32-1]+num[(j+tid/32*32)*1024+i+tid%32*32+1]+num[(j+tid/32*32-1)*1024+i+tid%32*32]+num[(j+tid/32*32+1)*1024+i+tid%32*32]);
result[(j+(bid*512+tid)/(SIZE_Y/SIZE_Y_T)*SIZE_Y_T)*SIZE_X+(i+(bid*256+tid)%(SIZE_Y/SIZE_Y_T)*SIZE_X_T)] = 2*num[(j+(bid*512+tid)/(SIZE_Y/SIZE_Y_T)*SIZE_Y_T)*SIZE_X+(i+(bid*256+tid)%(SIZE_Y/SIZE_Y_T)*SIZE_X_T)]+3*(num[(j+(bid*512+tid)/(SIZE_Y/SIZE_Y_T)*SIZE_Y_T+1)*SIZE_X+(i+(bid*256+tid)%(SIZE_Y/SIZE_Y_T)*SIZE_X_T)]+num[(j+(bid*512+tid)/(SIZE_Y/SIZE_Y_T)*SIZE_Y_T-1)*SIZE_X+(i+(bid*256+tid)%(SIZE_Y/SIZE_Y_T)*SIZE_X_T)]+num[(j+(bid*512+tid)/(SIZE_Y/SIZE_Y_T)*SIZE_Y_T)*SIZE_X+(i+(bid*256+tid)%(SIZE_Y/SIZE_Y_T)*SIZE_X_T+1)]+num[(j+(bid*512+tid)/(SIZE_Y/SIZE_Y_T)*SIZE_Y_T)*SIZE_X+(i+(bid*256+tid)%(SIZE_Y/SIZE_Y_T)*SIZE_X_T-1)]);
}
}
}
int main()
{
int data[SIZE_Y*SIZE_X];
unsigned long long start;
unsigned long long end;
if(!InitCUDA()) {
printf("CUDA initializing Error!\n");
return 0;
}
printf("CUDA initialized.\n");
for(int j=0; j< SIZE_Y; j++) {
for(int i=0; i< SIZE_X; i++) {
data[j*SIZE_X+i] = rand()%10;
}
}
start = GetCycleCount();
int* gpudata, *result;
cudaMalloc((void**) &gpudata, sizeof(int) * SIZE_X*SIZE_Y);
cudaMalloc((void**) &result, sizeof(int) * SIZE_X*SIZE_Y);
end = GetCycleCount();
printf("Malloc time:%lu cycles\n", end-start);
cudaMemcpy(gpudata, data, sizeof(int) * SIZE_X*SIZE_Y, cudaMemcpyHostToDevice);
end = GetCycleCount();
printf("Data copy time:%lu cycles\n", end-start);
stencil<<<BLOCK_NUM, THREAD_NUM, 0>>>(gpudata, result);
end = GetCycleCount();
printf("Computing time:%lu cycles\n", end-start);
int data_t[SIZE_Y*SIZE_X];
cudaMemcpy(data_t, result, sizeof(int) * SIZE_X*SIZE_Y, cudaMemcpyDeviceToHost);
end = GetCycleCount();
printf("Result copy time:%lu cycles\n", end-start);
cudaFree(gpudata);
cudaFree(result);
//Sleep(1000);
end = GetCycleCount();
printf("Stencil(GPU):%lu cycles\n", end-start);
/*
int sum = 0;
for(int j = 1; j < SIZE_Y-1; j++) {
for(int i = 1; i < SIZE_X-1; i++) {
if(i%64 != 0 && i%64 != 63 && j%64 != 0 && j%64 != 63) {
//sum = 0.5*data[j*SIZE_X+i]+0.125*(data[j*SIZE_X+i-1]+data[j*SIZE_X+i+1]+data[(j-1)*SIZE_X+i]+data[(j+1)*SIZE_X+i]);
sum = 2*data[j*SIZE_X+i]+3*(data[j*SIZE_X+i+1]+data[j*SIZE_X+i-1]+data[(j+1)*SIZE_X+i]+data[(j-1)*SIZE_X+i]);
if(sum != data_t[j*SIZE_X+i]) {
printf("Result Error:%d %d s:%d d:%d\n", j, i, sum, data_t[j*SIZE_X+i]);
}
else {
printf("Result Correct:%d %d s:%d d:%d\n", j, i, sum, data_t[j*SIZE_X+i]);
}
}
}
}
*/
return 0;
}