社区
华为云计算
帖子详情
Hadoop伪分布式集群NN和ResourceManager突然启动不了了是什么原因
愁死人了
2015-06-12 10:43:17
...全文
2352
1
打赏
收藏
Hadoop伪分布式集群NN和ResourceManager突然启动不了了是什么原因
[图片]
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
1 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
Panda_Master
2015-07-17
打赏
举报
回复
你好,出现该问题的原因可能为:网络不通,或者没做互信。请排查网络或者做下互信
大数据开发技术.pdf
在 HDFS 中,NameNode 的主要功能是什么? 1 我们把目录结构及文件分块位置信息叫做元数据。Namenode 负责 维护整个 hdfs 文件系统的目录树结构,以及每一个文件所对应的 block 块信息(block 的 id,及所在的 datanode 服务器) 。 2 Namenode 节点负责确定指定的文件块到具体的 Datanode 结点的 映射关系。在客户端与数据节点之间共享数据 3 管理 Datanode 结点的状态报告, 包括 Datanode 结点的健康状态报 告和其所在结点上数据块状态报告,以便能够及时处理失效的数据结 点。 NameNode 与 SecondaryNameNode 的区别与联系? 1. NameNode 负责管理整个文件系统的元数据, 以及每一个路径 (文 件)所对应的数据块信息。2.SecondaryNameNode 主要用于定 期 合 并 命 名 空 间 镜 像 和 命 名 空 间 镜 像 的 编 辑 日 志 。 1.SecondaryNameNode 中保存了一份和 namenode 一致的镜 像文件(fsimage)和编辑日志(edits) 。2.在主 namenode 发生 故障时(假设没有及时备份数据) ,可以从 SecondaryNameNode HDFS 读数据流程? 1. 跟 namenode 通信查询元数据,找到文件块所在的 datanode 服务 器 2.挑选一台 datanode(就近原则,然后随机)服务器,请求建立 socket 流 3.datanode 开始发送数据(从磁盘里面读取数据放入流, 以 packet 为单位来做校验)4.客户端以 packet 为单位接收,先在 本地缓存,然后写入目标文
Hadoop
集群
中
Hadoop
需要启动哪些进程, 它们的作用分别是什么? 1.NameNode 它是
hadoop
中的主服务器,管理文件系统名称空间和 对 集 群 中 存 储 的 文 件 的 访 问 , 保 存 有 metadate 。 2.SecondaryNameNode 它不是 namenode 的冗余守护进程,而是 提供周期检查点和清理任务。 帮助
NN
合并 editslog, 减少
NN
启动时 间。3.DataNode 它负责管理连接到节点的存储(一个
集群
中可以有 多个节点) 。每个存储数据的节点运行一个 datanode 守护进程。 4.
Resource
Manager
(JobTracker) JobTracker 负责调度 DataNode 上的工作。每个 DataNode 有一个 TaskTracker,它们执行实际工作。5.Node
Manager
(TaskTracker) 执行任务 6.DFSZKFailoverController 高可用时它负责监控
NN
的状 态,并及时的把状态信息写入 ZK。它通过一个独立线程 周期性的调用
NN
上的一个特定接口来获取
NN
的健康状态。FC 也有 选择谁作为 Active
NN
的权利,因为最多只有两个节点,目前选择策略 还比较简单(先到先得,轮换)7.JournalNode 高可用情况下存放 namenode 的 editlog 文件. 在 CentOS 环境下,按照
伪
分布方式安装和配置
Hadoop
平台的主要 过程。 1.
hadoop
安装包下载 2、
hadoop
安装包解压 3、
hadoop
伪
分布式
环境搭建环境搭建步骤如下:1、将
hadoop
安装目录添加到系统环 境变量(~/.bash_profile)2、配置
hadoop
环境的配置文件
hadoop
-env.sh3、配置
hadoop
核心文件 core-site.xml4、配置 HDFS 文件 hafs-site.xml Mapreduce 中,Partitioner 操作的作用? MapReduce 提供 Partitioner 接口,它的作用就是根据 key 或 value 及 reduce 的数量 来决定当前的这对输出数据最终应该交由哪个 reduce task 处理。默认 对 key hash 后再以 reduce task 数量取模。默认的取模方式只是为了 平均 reduce 的处理能力, 如果用户自己对 Partitioner 有需求, 可以订 制并设置到 job 上。 HDFS 中的写数据流程。 (1) Client 向 NameNode 发起文件写入的请求。 (2) NameNode 根 据文件大小和文件块配置情况,返回给 Client 它所管理部分 DataNode 的信息。 (3) Client 将文件划分为多个 Block,根据 DataNode 的地址信息,按顺序写入到每一个 DataNode
创建并配置一个
伪
分布式
Hadoop
3.x版本
集群
(三)
为了保证应用高可用性,一般我们都会搭建一个应用的
集群
环境,这样即使其中一个应用出现故障,
集群
中的其他应用仍可继续对外提供访问。本章将介绍如何安装和配置一个
伪
分布式
集群
。
hadoop
环境准备搭建一个简单的
伪
分布式
Hadoop
集群
操作
hadoop
集群
使用
hadoop
运行测试程序本文中我们使用一台机器完成了
Hadoop
的
伪
分布式
集群
部署,在实际的生成活动中,此种模式只能用于开发人员进行测试使用,下一章将介绍如何搭建一个
Hadoop
的完全
分布式
集群
,敬请期待。
hadoop
全
分布式
集群
配置
Hadoop
实现了一个
分布式
文件系统(
Hadoop
Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。本课程讲解搭建
hadoop
集群
的全过程,从安装vmware,centos开始,从本地模式,
伪
分布式
到全
分布式
,讲解实现经典案例wordcount结束,全方位讲解
hadoop
的操作细节,带你完成
hadoop
的安装和入门
大数据分析入门-
Hadoop
伪
分布式
搭建(
hadoop
-2.7.7)
Hadoop
伪
分布式
搭建(
hadoop
-2.7.7)
Hadoop
完全
分布式
集群
搭建过程(HA高可用)
使用Centos7来进行完全
分布式
的
集群
搭建,一般我们用
伪
分布式
的
集群
就可以了,不需要配置完全
分布式
的
集群
和我们搭建
伪
分布式
集群
一样,我们首先要现在好安装包,以及我们需要配置配置JDK,SSH免秘钥登陆,以及Zookeeper
分布式
的搭建等,下面就开始我们的搭建过程 一、配置Linux虚拟机 1.配置主机名以及主机映射 我们配置
集群
环境的时候,设置固定的主机名和主机映射能够方便的让我我们使用 修...
华为云计算
917
社区成员
645
社区内容
发帖
与我相关
我的任务
华为云计算
华为云计算论坛,提供全面深入的云计算前景分析、丰富的技术干货、程序样例,分享华为云前沿资讯动态,方便开发者快速成长与发展,欢迎提问、互动,多方位了解云计算!
复制链接
扫一扫
分享
社区描述
华为云计算论坛,提供全面深入的云计算前景分析、丰富的技术干货、程序样例,分享华为云前沿资讯动态,方便开发者快速成长与发展,欢迎提问、互动,多方位了解云计算!
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章
 愁死人了 2015-06-12 10:43:17
愁死人了 2015-06-12 10:43:17 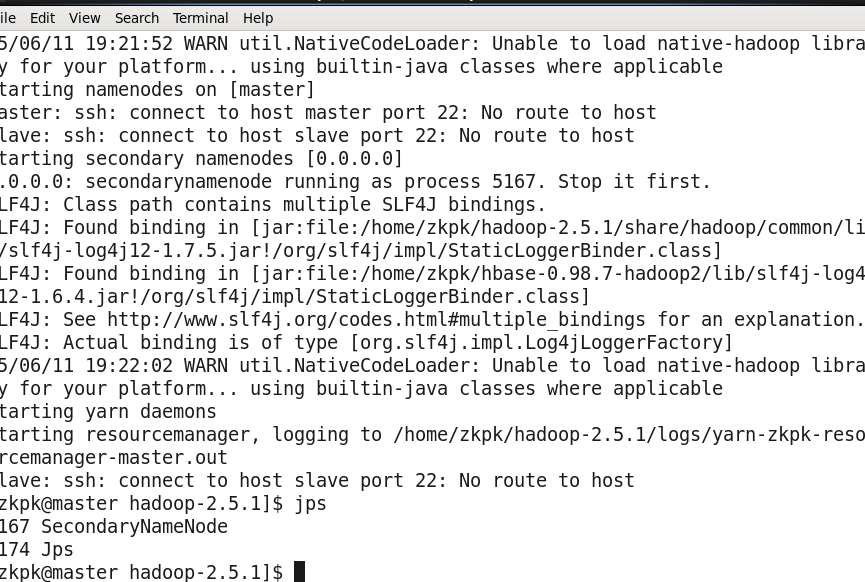




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

