社区
Java
帖子详情
如何抓取用js分页的下一页数据
蔡小波
2015-06-20 12:11:32
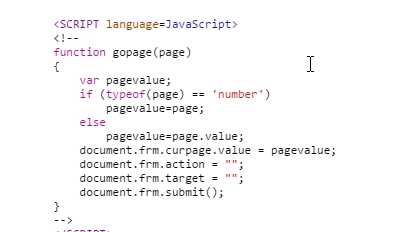
<a class="opac_blue1" href="javascript:gopage(2)">下一页</a>
它分页是javascript分页的,我提交表单上去一样获取不了,它的地址固定是http://61.142.33.201:8080/opac_two/search2/searchout.jsp这个,刚学不久,请问如何才能获取到下一页数据,我用httpclient抓的
...全文
691
3
打赏
收藏
如何抓取用js分页的下一页数据
下一页 它分页是javascript分页的,我提交表单上去一样获取不了,它的地址固定是http://61.142.33.201:8080/opac_two/search2/searchout.jsp这个,刚学不久,请问如何才能获取到下一页数据,我用httpclient抓的
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
3 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
bichir
2015-06-23
打赏
举报
回复
你对他提交的参数做一下分析,你可以发现他用post提交了很多参数到服务器, 所以你在用httpclient抓取数据时就得提交这些参数。 具体是哪些你可以点右键审查元素<input>这种标签里的东西,名字就是标签名name 比如你获取到了第一页数据后,要获取第二页就得把curpage加一个一,然后再用httplient请求一次。 其实我看了这网站,他里面有一个size参数你可以把这个参数设为足够大,比如2000000000,然后curpage设为1, 你就可以最多一次获取2000000000条数据了,就可以不用翻页或分多次用httpclient获取了
X元素
2015-06-23
打赏
举报
回复
做翻页,前台传当前显示数据条数,当前页,后台根据使用数据库不同,做相应的查询、
蔡小波
2015-06-20
打赏
举报
回复
顶顶...............
10种漂亮
JS
网站
分页
代码
10种漂亮
JS
网站
分页
代码,做网站时用的漂亮动感代码。
JS
做的原生
分页
JS
做的原生
分页
JS
-
数据
库page
分页
样式.rar
JS
-
数据
库page
分页
样式.rar
JS
-
数据
库page
分页
样式.rar
JS
-
数据
库page
分页
样式.rar
JS
-
数据
库page
分页
样式.rar
10种JavaScript
分页
效果
自已以前学习的时候收集的! 传上来和大家分享
jQuery实现
分页
功能(含ajax请求、后台
数据
、附完整demo)
主要给大家介绍了关于jQuery实现
分页
功能的相关资料,主要包含ajax请求和后台
数据
,文末给出了完整的demo示例,对大家具有一定的参考价值,需要的朋友们下面来一起看看吧。
Java
51,409
社区成员
86,079
社区内容
发帖
与我相关
我的任务
Java
Java相关技术讨论
复制链接
扫一扫
分享
社区描述
Java相关技术讨论
java
spring boot
spring cloud
技术论坛(原bbs)
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享






