2,759
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
import requests
import bs4
url = "http://image.baidu.com/activity/starfans/2220260263?&albumtype=0"
r = requests.get(url)
if r.status_code == 200:
re_file = r.text
soup = bs4.BeautifulSoup(re_file)
#print soup.prettify()
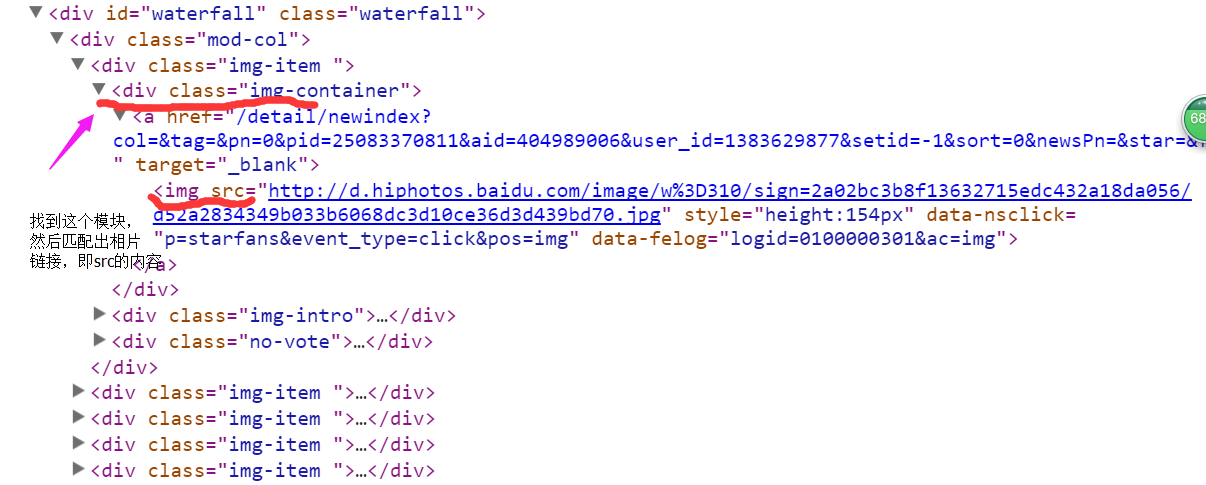
print soup.find(name="div", attrs={"class":"img-container"}) #找到"<div class=img-container"这个模块,由于无法找到该模#块,所以还没有写匹配项
else:
print("error 404!...")