Python 如何爬取相同url下,多个页面的链接内容
初学Python爬虫,计划从大连商品交易所网站,爬取每日发布的PVC市场价格数据(
http://www.dce.com.cn/portal/cate?cid=1329986308100)。
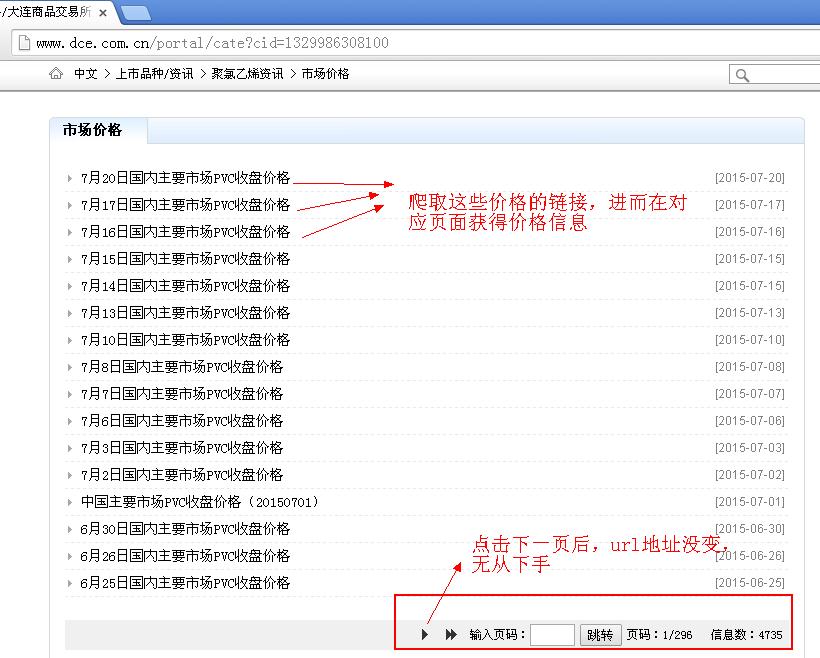
目前已能够从以上链接的第一页,把该页显示的市场价格链接爬取下来,并提取出价格信息(github托管的代码
https://github.com/songwill/download-pvc-data/blob/master/pagelink.txt)。
但是点击第二页后,发现url和第一页显示的一模一样,不能用学过的循环去爬取接下来的第2页、第3页……的价格链接。求大神们指点下:
1、为什么不同页面内容会在同一个url下显示
2、要爬取后续页面里的链接,代码该如何写


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享









