




64,643
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



 ,你说的很有意义
,你说的很有意义



 [/quote]
[/quote]
 [/quote]
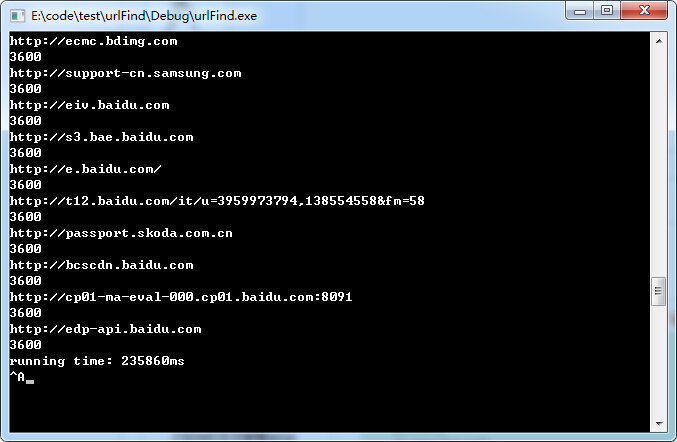
测试一下慢在那里, find的参数改成引用
[/quote]
测试一下慢在那里, find的参数改成引用
void find_largeTH(unordered_map<string,int> &urlhash)
{
for(auto &item : urlhash){
pq.push({item.first,item.second});
if(pq.size()>100) pq.pop();
}
}
void insertUrl(string url)
{
++hash_url[url];
}
// urlFind.cpp : 定义控制台应用程序的入口点。
//
// sortUrl.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include <vector>
#include <map>
#include <fstream>
#include <iostream>
#include <string>
#include <algorithm>
#include <unordered_map>
#include <queue>
#include "ComputeTime.h"
using namespace std;
typedef pair<string, int> PAIR;
struct info
{
string url;
int cnt;
bool operator<(const info &r) const
{
return cnt<r.cnt;
}
};
unordered_map<string,int> hash_url;
priority_queue<info> pq;
//
//
void find_largeTH(unordered_map<string,int> &urlhash)
{
unordered_map<string,int>::iterator iter = urlhash.begin();
info temp;
for (; iter!= urlhash.end();++iter)
{
temp.url = iter->first;
temp.cnt = iter->second;
pq.push(temp);
}
for (int i = 0; i != 100; ++i)
{
cout<<pq.top().url<<endl;
cout<<pq.top().cnt<<endl;
pq.pop();
}
}
//void find_largeTH(unordered_map<string,int> &urlhash)
//{
// for(auto& item : urlhash)
// {
// pq.push(item.first,item.second);
// if(pq.size()>100) pq.pop();
// }
//}
void insertUrl(string url)
{
++hash_url[url];
}
//void insertUrl(string url)
//{
//
// pair<unordered_map<string ,int>::iterator, bool> Insert_Pair;
// Insert_Pair = hash_url.insert(unordered_map<string, int>::value_type(url,1));
//
// if (Insert_Pair.second == false)
// {
// (Insert_Pair.first->second++);
// }
//
//}
int _tmain(int argc, _TCHAR* argv[])
{
fstream URLfile;
char buffer[1024];
URLfile.open("url.txt",ios::in|ios::out|ios::binary);
if (! URLfile.is_open())
{ cout << "Error opening file"; exit (1); }
else
{
cout<<"open file success!"<<endl;
}
ComputeTime cp;
cp.Begin();
int i = 0;
while (!URLfile.eof())
{
URLfile.getline (buffer,1024);
//cout << buffer << endl;
string temp(buffer);
//cout<<i++<<endl;
insertUrl(temp);
}
double insert_time = cp.End();
cp.Begin();
find_largeTH(hash_url);
double sort_time = cp.End();
cout<<"insert running time: "<<insert_time<<"ms"<<endl;
cout<<"sort running time: "<<sort_time<<"ms"<<endl;
cout<<"running time: "<<insert_time + sort_time<<"ms"<<endl;
getchar();
//system("pause");
return 0;
}
 [/quote]
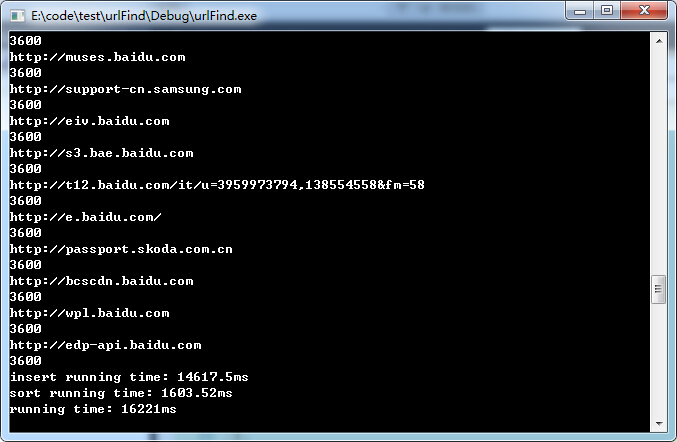
在url统计中没必要构造pair和iterator, 我认为这里还是有性能损耗的, 当然你可以在网上找个其它hash的方法替换unordered_map中的hash试一下.
[/quote]
大牛有没有兴趣,写点代码,嘿嘿黑
[/quote]
在url统计中没必要构造pair和iterator, 我认为这里还是有性能损耗的, 当然你可以在网上找个其它hash的方法替换unordered_map中的hash试一下.
[/quote]
大牛有没有兴趣,写点代码,嘿嘿黑



