


37,738
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
#coding: utf-8
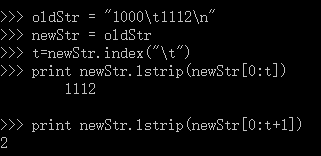
oldStr = "1000\t1112\n"
newStr = oldStr
t=newStr.index("\t")
newStr = newStr.lstrip(newStr[0:t])
]newStr = newStr.lstrip("\t")
newStr = newStr.rstrip("\n")
if int(newStr)>1000:
print 'ok'
else:
print 'sorry'
#coding: utf-8
oldStr = "1000\t1112\n"
newStr = oldStr
t=newStr.index("\t")
newStr = newStr.lstrip(newStr[0:t+1])
newStr = newStr.rstrip("\n")
if int(newStr)>1000:
print 'ok'
else:
print 'sorry'
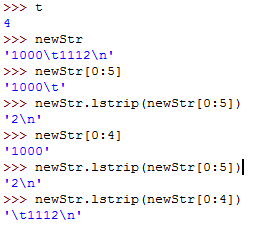




"1000\t1112\n".lstrip("1") # "000\t1112\n"
"1000\t1112\n".lstrip("0") # "1000\t1112\n"
"1000\t1112\n".lstrip("10") # "\t1112\n"
"1000\t1112\n".lstrip("10\t") # "2\n"
"1000\t1112\n".lstrip("1000\t") # "2\n"oldStr = "1000\t1112\n"
newStr = oldStr
t=newStr.index("\t") # t : 4
# newStr = newStr.lstrip(newStr[0:t+1]) # 将这一行分解为下面两行
temp = newStr[0:t+1] # temp: '1000\t'
newStr = newStr.lstrip(temp) # newStr: '2\n'
newStr = newStr.rstrip("\n") # newStr: '2'
#coding: utf-8
oldStr = "1000\t1112\n"
newStr = oldStr[oldStr.index('\t'):].lstrip('\t').rstrip('\n')
if int(newStr)>1000:
print 'ok'
else:
print 'sorry'

#coding: utf-8
oldStr = "1000\t1112\n"
newStr = oldStr
t=newStr.index("\t")
newStr=newStr.lstrip(newStr[0:t])
newStr = newStr.rstrip("\n")
if int(newStr)>1000:
print 'ok'
else:
print 'sorry' 
