solr版本 solr-4.10.4,mmseg4j版本 mmseg4j-1.9.1
schema.xml里的配置,
<!-- mmseg4j-->
<fieldType name="text_mmseg4j_complex" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="dic" />
</analyzer>
</fieldType>
<fieldType name="text_mmseg4j_maxword" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" dicPath="dic"/>
</analyzer>
</fieldType>
<fieldType name="text_mmseg4j_simple" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="dic"/>
</analyzer>
</fieldType>
<!-- mmseg4j-->
<!-- general -->
<field name="id" type="string" indexed="true" stored="true" multiValued="false" required="true"/>
<field name="type" type="string" indexed="true" stored="true" multiValued="false" />
<field name="name" type="text_mmseg4j_maxword" indexed="true" stored="true" />
<field name="core0" type="string" indexed="true" stored="true" multiValued="false" />
<field name="_version_" type="long" indexed="true" stored="true"/>
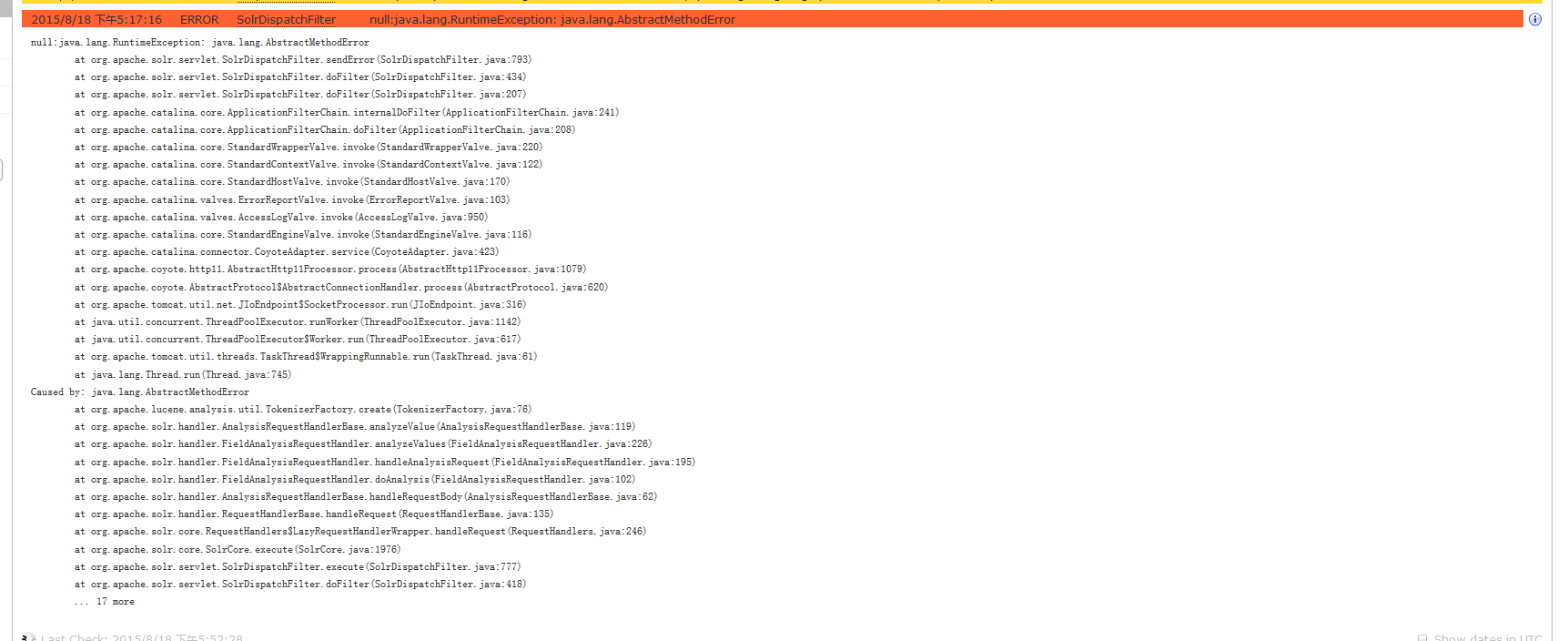
错误提示:

log:

 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


 问题解决了吗?
问题解决了吗?
 就这么沉了么。。。。
就这么沉了么。。。。
