




37,741
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
driver=webdriver.PhantomJS()
driver.get('http://www.huazhu.com')
wait = ui.WebDriverWait(driver,10)
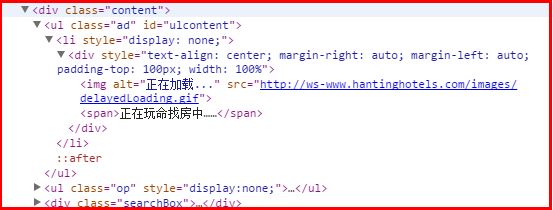
details = driver.find_element_by_xpath("//div[@class='content']/ul/li")
print details.text
filename = os.path.basename(pic_url)
urllib.urlretrieve(pic_url, 'E:\\Picture\\'+filename)
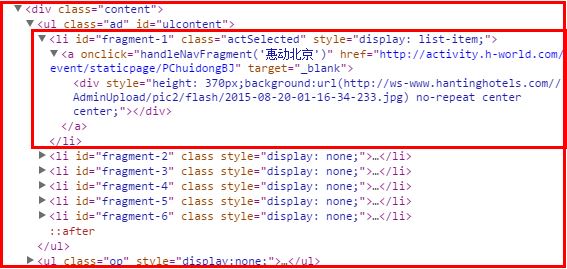
<div style="height: 370px;background:url(http://ws-www.hantinghotels.com//AdminUpload/pic2/flash/2015-06-18-04-00-07-380.jpg)no-repeat center center;"></div>
# coding=utf-8
import urllib
import time
import re
import os
strs = "<div style='height: 370px;background:url(http://ws-www.hantinghotels.com//AdminUpload/pic2/flash/2015-08-20-01-16-34-233.jpg) no-repeat center center;'></div>"
start = strs.find(r'http')
end = strs.find(r')')
url = strs[start:end]
print url
filename = os.path.basename(url)
urllib.urlretrieve(url, 'E:\\'+filename)




