


81,115
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享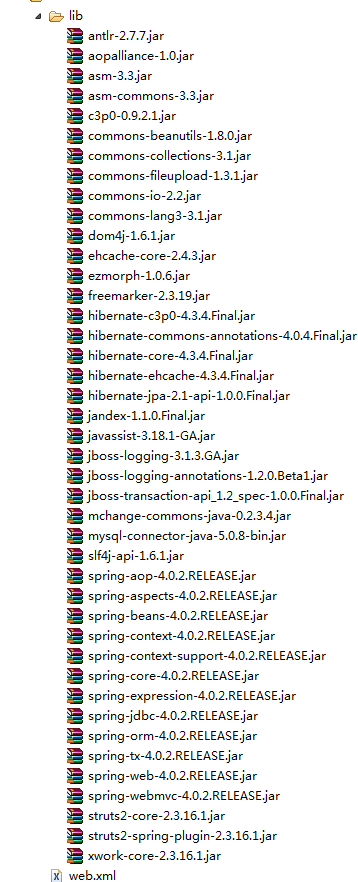
信息: Starting Servlet Engine: Apache Tomcat/6.0.13
2015-9-17 11:17:10 org.apache.catalina.core.StandardContext listenerStart
严重: Exception sending context initialized event to listener instance of class org.springframework.web.context.ContextLoaderListener
java.lang.NoClassDefFoundError: org/apache/commons/logging/LogFactory
at org.springframework.web.context.ContextLoader.initWebApplicationContext(ContextLoader.java:282)
at org.springframework.web.context.ContextLoaderListener.contextInitialized(ContextLoaderListener.java:106)
at org.apache.catalina.core.StandardContext.listenerStart(StandardContext.java:3827)
at org.apache.catalina.core.StandardContext.start(StandardContext.java:4334)
at org.apache.catalina.core.ContainerBase.addChildInternal(ContainerBase.java:791)
at org.apache.catalina.core.ContainerBase.addChild(ContainerBase.java:771)
at org.apache.catalina.core.StandardHost.addChild(StandardHost.java:525)
at org.apache.catalina.startup.HostConfig.deployDirectory(HostConfig.java:920)
at org.apache.catalina.startup.HostConfig.deployDirectories(HostConfig.java:883)
at org.apache.catalina.startup.HostConfig.deployApps(HostConfig.java:492)
at org.apache.catalina.startup.HostConfig.start(HostConfig.java:1138)
at org.apache.catalina.startup.HostConfig.lifecycleEvent(HostConfig.java:311)
at org.apache.catalina.util.LifecycleSupport.fireLifecycleEvent(LifecycleSupport.java:117)
at org.apache.catalina.core.ContainerBase.start(ContainerBase.java:1053)
at org.apache.catalina.core.StandardHost.start(StandardHost.java:719)
at org.apache.catalina.core.ContainerBase.start(ContainerBase.java:1045)
at org.apache.catalina.core.StandardEngine.start(StandardEngine.java:443)
at org.apache.catalina.core.StandardService.start(StandardService.java:516)
at org.apache.catalina.core.StandardServer.start(StandardServer.java:710)
at org.apache.catalina.startup.Catalina.start(Catalina.java:566)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at org.apache.catalina.startup.Bootstrap.start(Bootstrap.java:288)
at org.apache.catalina.startup.Bootstrap.main(Bootstrap.java:413)
Caused by: java.lang.ClassNotFoundException: org.apache.commons.logging.LogFactory
at org.apache.catalina.loader.WebappClassLoader.loadClass(WebappClassLoader.java:1358)
at org.apache.catalina.loader.WebappClassLoader.loadClass(WebappClassLoader.java:1204)
at java.lang.ClassLoader.loadClassInternal(ClassLoader.java:320)
... 26 more




<filter>
<filter-name>struts2</filter-name>
<filter-class>org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter</filter-class>
</filter> 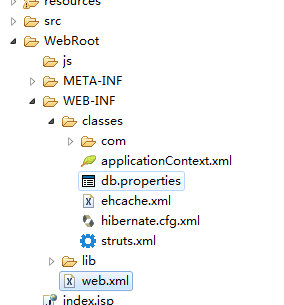 新手,谢谢了![/quote]
楼主,资源包添加到编译路径了吗?右键一下项目,config build path,然后在弹出的对话框中看一下lib目录下的jar是否全,不全的话代表资源jar包没有配置到项目的可编译路径中。[/quote]
jar包编译路径中跟我发帖时的截图一致的,是缺少什么吗?
新手,谢谢了![/quote]
楼主,资源包添加到编译路径了吗?右键一下项目,config build path,然后在弹出的对话框中看一下lib目录下的jar是否全,不全的话代表资源jar包没有配置到项目的可编译路径中。[/quote]
jar包编译路径中跟我发帖时的截图一致的,是缺少什么吗?<filter>
<filter-name>struts2</filter-name>
<filter-class>org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter</filter-class>
</filter> <filter>
<filter-name>struts2</filter-name>
<filter-class>org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter</filter-class>
</filter> 
