社区
Hadoop生态社区
帖子详情
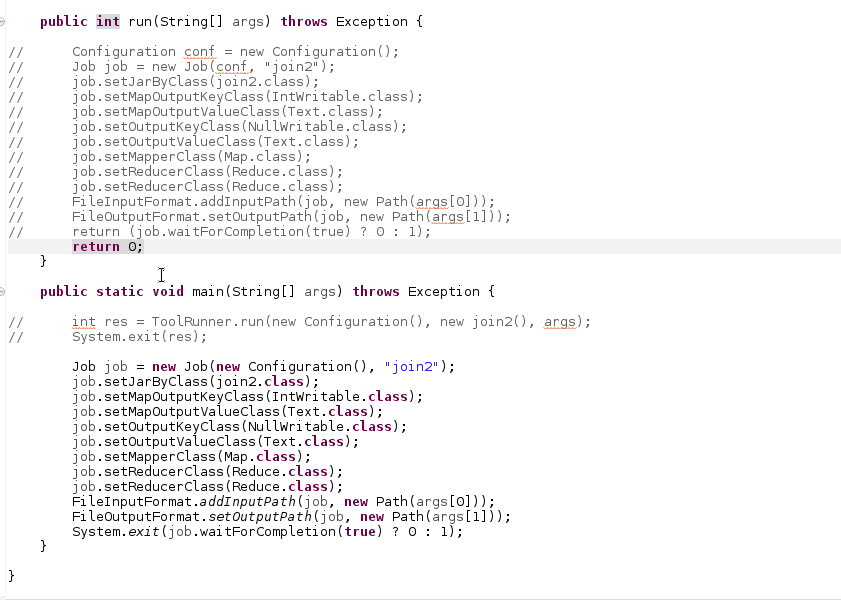
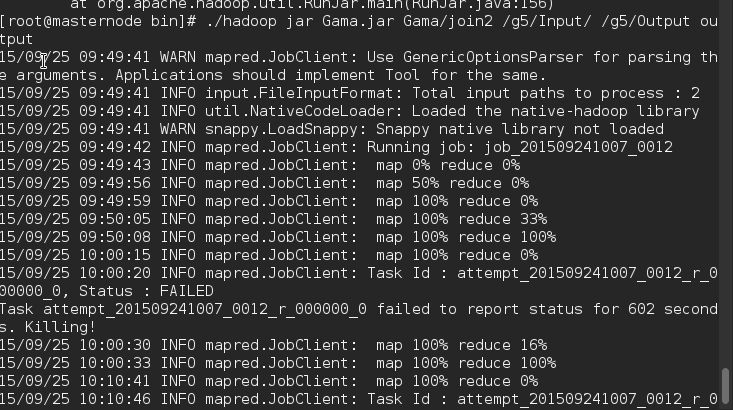
map 100% reduce100% 后就 map100% reduce0% 就被kill了
请叫我林平之
2015-09-25 10:10:42
大神求助
...全文
451
3
打赏
收藏
map 100% reduce100% 后就 map100% reduce0% 就被kill了
大神求助
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
3 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
夜无边CN
2015-09-26
打赏
举报
回复
引用 2 楼 u013212346 的回复:
没有啊 就运行了这个
代码应该没有问题。运行的时候到 50030上看一下有没有详细的错误日志。 设置两个 job.setReducerClass(Reducer.class); 是什么意思?
请叫我林平之
2015-09-25
打赏
举报
回复
没有啊 就运行了这个
夜无边CN
2015-09-25
打赏
举报
回复
failed to report status for 602 second killing! 你有没重写其他的东西
hive执行count(*):Stage-1
map
= 0%,
reduce
= 0%
1、问题描述: 在hive的shell端执行:select count(*) from student;出现了下面问题(一直卡着): hive> select count(*) from student; WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions...
hive执行sql:stage-1
map
= 0
reduce
= 0
解决hive执行
map
阶段进度一直为0的办法
一个关于
Map
Join的测试用例
hive> create table lpx_
map
join as > SELECT '2012-04-17' as stat_date > ,b.admin_member_id > ,a.category_level2_id > ,b.keywords > ,sum(shownum
2016-09-23 18:45:10,950 Stage-6
map
= 60%,
reduce
= 0%, Cumulative CPU 1740.12 sec
hive (obd_message)> CREATE TABLE locus_travel_cent4 as > select tb3.obd_id,tb3.start_time,tb3.end_time, tb3.mc[2] as dis,tb3.mc[3]*tb4.pl*tb4.xs/1.8 as disFuel
map
reduce
作业
reduce
被大量
kill
掉
之前有一段时间,我们的hadoop2.4集群压力非常大,导致提交的job出现大量的
reduce
被
kill
掉,相同的job运行时间比在hadoop0.20.203上面长了很多,这个问题其实是
reduce
任务启动时机的问题,由于yarn中没有
map
slot和
reduce
slot的概念,且ResourceManager也不知道
map
task和
reduce
task之间的依赖关系,因此MRAppMaster自己需要设计资源申请策略以防止因
reduce
task过早启动照成资源利用率低下和
map
task因分
Hadoop生态社区
20,808
社区成员
4,690
社区内容
发帖
与我相关
我的任务
Hadoop生态社区
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
复制链接
扫一扫
分享
社区描述
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章






 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
