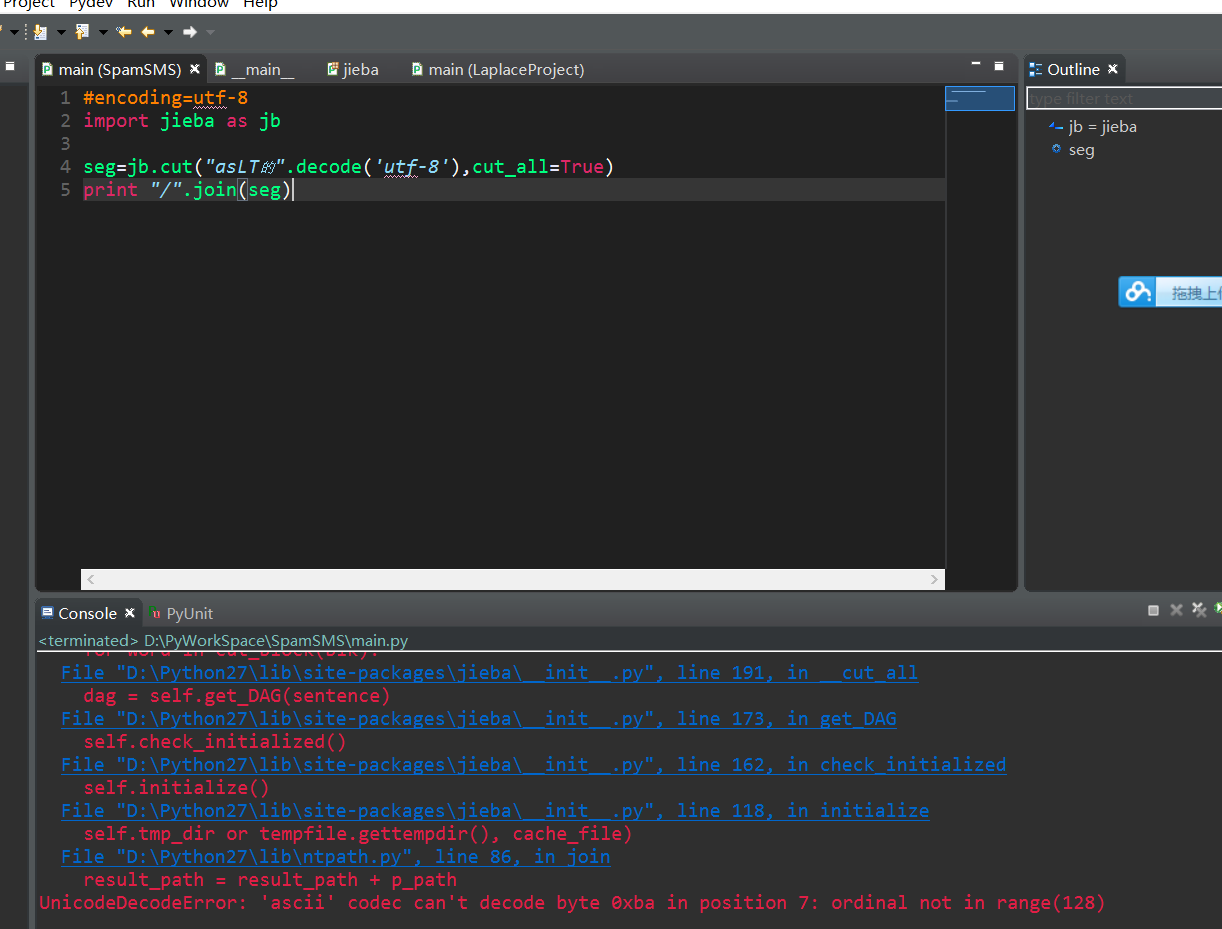
安装的结巴分词版本是python2.7.10的0.37
我的基本代码如下
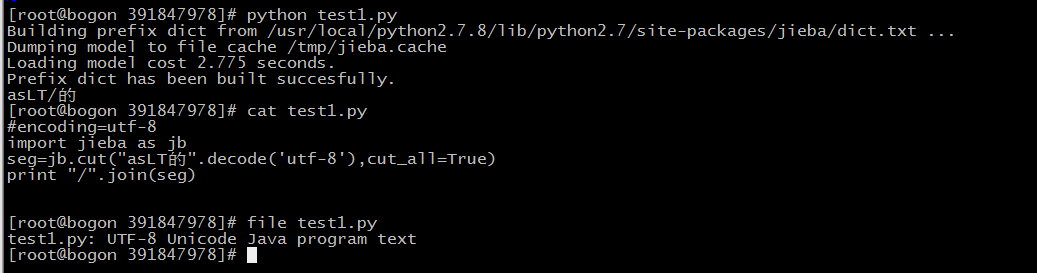
#encoding=utf-8
import jieba as jb
seg=jb.cut("asLT的".decode('utf-8'),cut_all=True)
print "/".join(seg)
但是运行分词的时候出现错误提示:
result_path = result_path + p_path
UnicodeDecodeError: 'ascii' codec can't decode byte 0xba in position 7: ordinal not in range(128)
目测是编码问题,如何解决?





 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

