社区
非技术区
帖子详情
从ubuntu software center安装matlab,一直没有安装完成,也没法取消,怎么办?
密函一封
2015-11-01 11:18:31
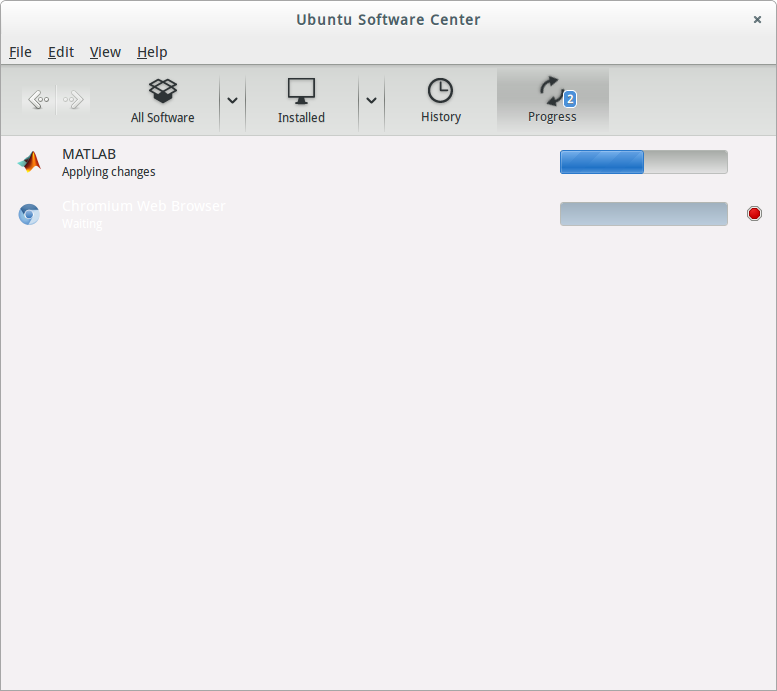
请看图,很奇怪啊!继续等着吗?进度条一直都没动,感觉安装不上啊!?
想取消掉,该怎么取消呢? 不取消我下边想安装浏览器也安不上。
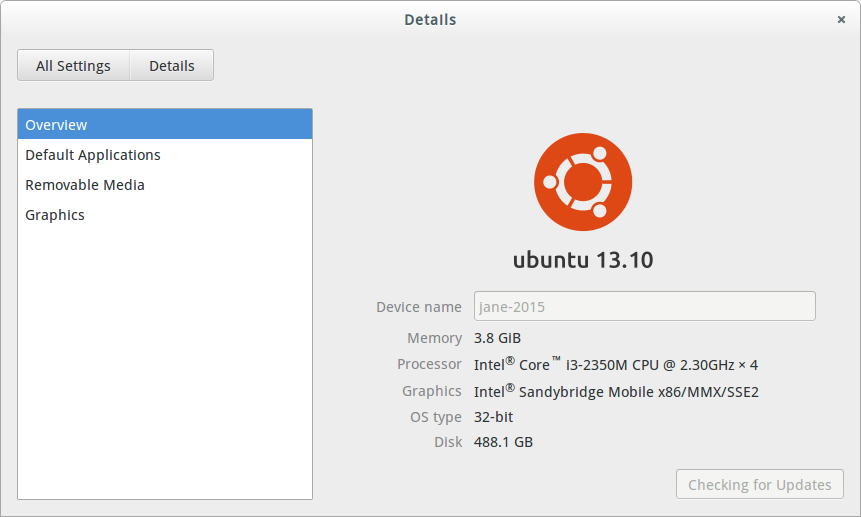
这是系统详细信息,不知是否有用。
...全文
664
4
打赏
收藏
从ubuntu software center安装matlab,一直没有安装完成,也没法取消,怎么办?
请看图,很奇怪啊!继续等着吗?进度条一直都没动,感觉安装不上啊!? 想取消掉,该怎么取消呢? 不取消我下边想安装浏览器也安不上。 这是系统详细信息,不知是否有用。
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
4 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
密函一封
2015-11-13
打赏
举报
回复
2楼回答有帮助,看了详细信息,软件中心提供的确实不是完整的安装包,只是整合已安装好的MATLAB,使其用起来更贴近Debian系统版本
密函一封
2015-11-13
打赏
举报
回复
谢谢大家的回答了…… 最后自己下了安装包
ChampangeYo
2015-11-02
打赏
举报
回复
这个matlab好像不是完整版的。只是提供了安装Matlab的简易方法。你看看英文介绍。
尽头2nxszn98
2015-11-01
打赏
举报
回复
话说我很少用 ubuntu 的软件中心,一般都是在网上下载好资源,然后手动安装
i-vector的工具箱
MSR Identity Toolbox: A
Matlab
Toolbox for Speaker Recognition Research Version 1.0 Seyed Omid Sadjadi, Malcolm Slaney, and Larry Heck Microsoft Research, Conversational Systems Research
Center
(CSRC) s.omid.sadjadi@gmail.com, {mslaney,larry.heck}@microsoft.com This report serves as a user manual for the tools available in the Microsoft Research (MSR) Identity Toolbox. This toolbox contains a collection of
Matlab
tools and routines that can be used for research and development in speaker recognition. It provides researchers with a test bed for developing new front-end and back-end techniques, allowing replicable evaluation of new advancements. It will also help newcomers in the field by lowering the “barrier to entry”, enabling them to quickly build baseline systems for their experiments. Although the focus of this toolbox is on speaker recognition, it can also be used for other speech related applications such as language, dialect and accent identification. In recent years, the design of robust and effective speaker recognition algorithms has attracted significant research effort from academic and commercial institutions. Speaker recognition has evolved substantially over the past 40 years; from discrete vector quantization (VQ) based systems to adapted Gaussian mixture model (GMM) solutions, and more recently to factor analysis based Eigenvoice (i-vector) frameworks. The Identity Toolbox provides tools that implement both the conventional GMM-UBM and state-of-the-art i-vector based speaker recognition strategies. A speaker recognition system includes two primary components: a front-end and a back-end. The front-end transforms acoustic waveforms into more compact and less redundant representations called acoustic features. Cepstral features are most often used for speaker recognition. It is practical to only retain the high signal-to-noise ratio (SNR) regions of the waveform, therefore there is also a need for a speech activity detector (SAD) in the fr
ubuntu
下
安装
Matlab
(注:本文部分内容转自互联网) 一.
安装
程序Step 1:下载
matlab
的
安装
文件至主目录下,讲
matlab
文件重命名为Mathworks.
Matlab
.R2012a.Unix.isoStep 2:挂载iso文件 sudo mount -o loop Mathworks.
Matlab
.R2012a.UNIX.iso /mnt Step 3: 跳转到挂载目录 1 cd /mnt...
U7
Ubuntu
系统的U盘启动与
安装
本课程是《U盘分区与启动》课程的深化,聚焦于广泛应用的
Ubuntu
系统,介绍用U盘来启动和
安装
Ubuntu
系统,课程内容包括:
Ubuntu
系统有什么特点? 如何制作U盘上的
Ubuntu
系统? 如何利用U盘上的
Ubuntu
系统
安装
硬盘上...
Ubuntu
(Linux)下
安装
Matlab
依然觉得
安装
Ubuntu
下给
Matlab
建立desktop 快捷方式
Laji
software
center
, laji
matlab
-support, 还是这个好使. 用
software
和sudo apt-get install
matlab
-support装
matlab
图标引导,把我电脑搞崩了,辣鸡!下面的code非常好使. 我在
Ubuntu
下是用的默认
安装
的,路径为/usr/local/
MATLAB
/R2018b sudo gedit /usr/sha...
非技术区
427
社区成员
2,550
社区内容
发帖
与我相关
我的任务
非技术区
非技术问题的乐园
复制链接
扫一扫
分享
社区描述
非技术问题的乐园
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



