算是一个基础语法问题了,不过在网上没有找到说得比较精准的资料。
这里把自己的研究结果分享一下,与大家共勉
 char
char
与C/C++不同,Java中的char类型是双字节(16位)的,也就是说
不管是半角字符还是全角字符都可以
用一个char表示。所以通常情况下,可以放心的使用String类的以char为单位的任何方法,完全没有问题。
code-point
中文译为“代码点”,这个概念是用于处理四字节(32位)Unicode编码的,也就是UCS-4字符集
(请参见
http://bbs.csdn.net/topics/390443113#post-394385624)。如果字串中存在UCS-4字符,
那么
一个此类字符对应两个char,即一个code-point对应两个char。
UCS-4
引入了平面(plane)的概念,通常使用的双字节(16位)的部分被定义为“平面0”,
目前已定义的平面序号为0~2,外加一个E平面。
参考资料:
iteye技术博客:
http://thoughtfly.iteye.com/blog/977495
维基百科:
https://zh.wikibooks.org/wiki/Unicode/0000-0FFF
Unicode官网:
http://unicode.org/charts/
实验
借助维基百科的页面,找到位于“平面2”的、编码为20001(写全了就是0x00020001)的汉字
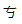
,
粘贴到Word里面,看到字体自动变为“SimSun-ExtB”(宋体增补,SimSun是“宋体”的英文译法)。
执行“插入|字符|其它符号”,看到它的编码就是20001,子集是“扩展字符-平面2”。
粘贴到IDEA中看看,自动做了转换:
String s = "\uD840\uDC01";



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


