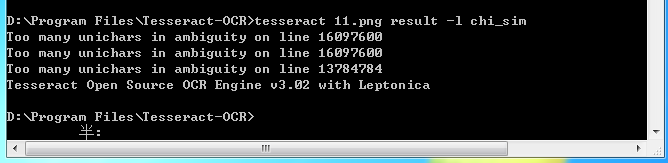
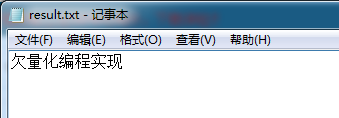
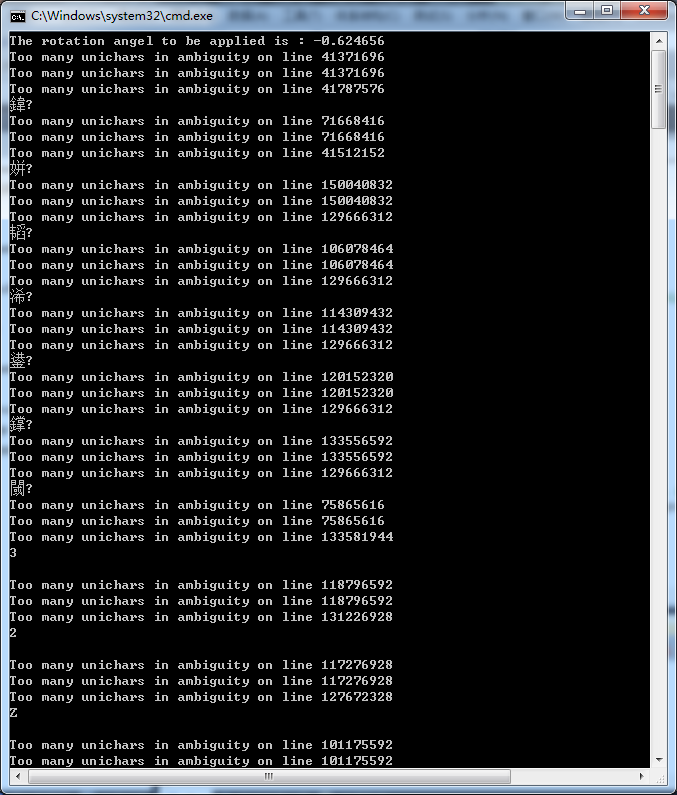
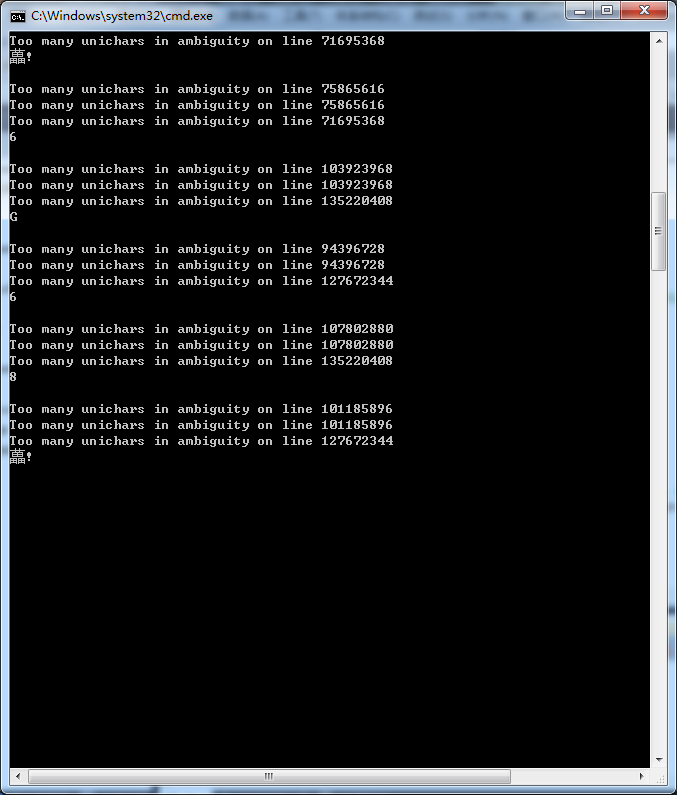
识别结果还算可以,但是应用到具体的C++/OpenCV程序时候,就会出现更多的Too many unichars in ambiguity on line xxxxxxx类型的错误,而且识别出来的中文全是乱码。
请有经验的朋友帮忙指点。
...全文
14375打赏收藏
Tesseract进行中文识别出现Too many unichars in ambiguity on line 16097600
安装的版本是tesseract 3.02 进行简单的中文识别: 测试图片: 结果截图: 识别结果: 识别结果还算可以,但是应用到具体的C++/OpenCV程序时候,就会出现更多的Too many unichars in ambiguity on line xxxxxxx类型的错误,而且识别出来的中文全是乱码。 请有经验的朋友帮忙指点。



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享