17,377
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
 Nice.
的确把空值问题忽略了
Nice.
的确把空值问题忽略了
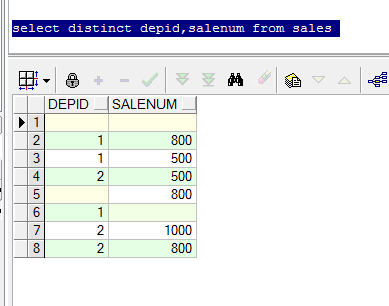
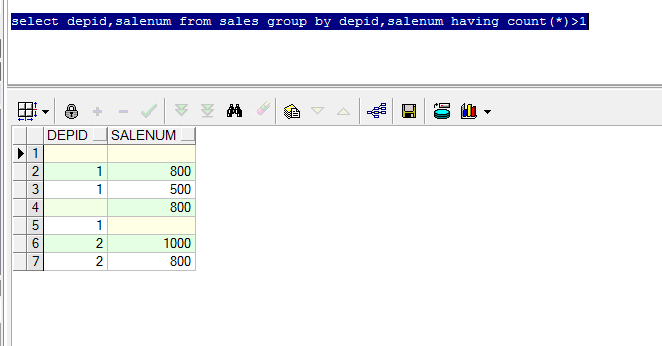
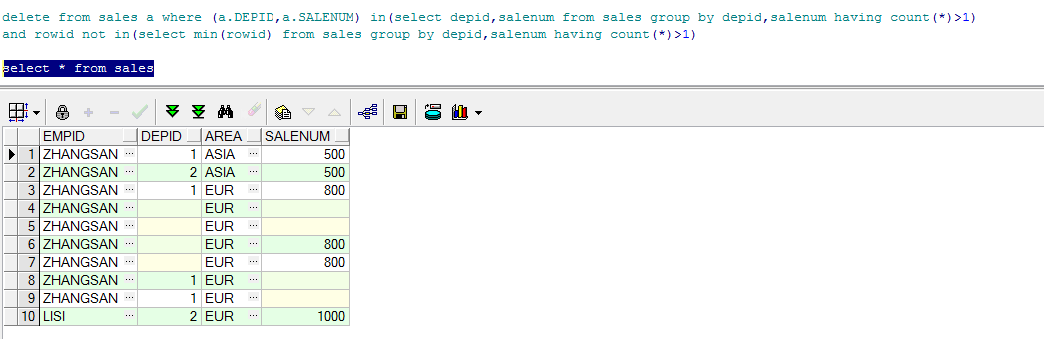
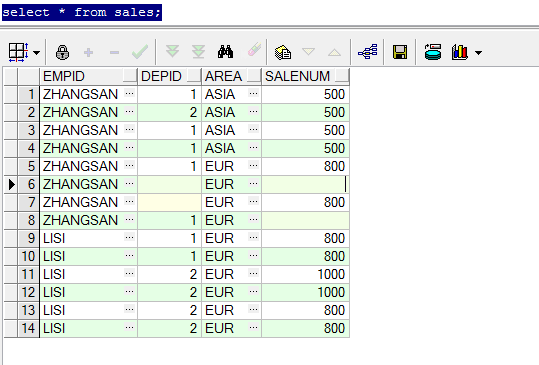
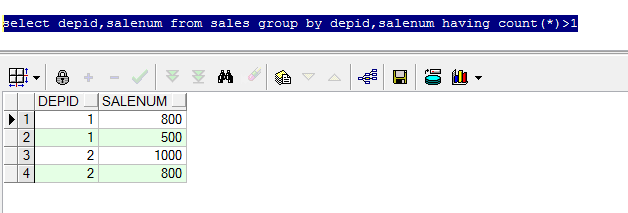
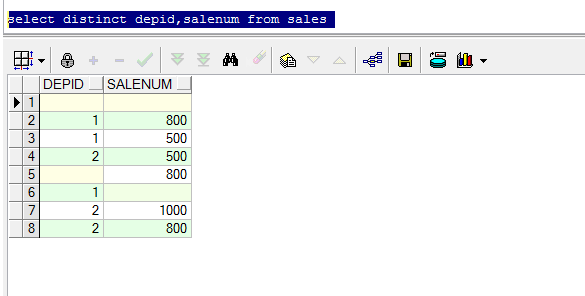

with t as (
select '1' as id,'a' as name from dual
union all
select '1' as id,'b' as name from dual
union all
select '2' as id ,'c' as name from dual
union all
select '' as id ,'d' as name from dual
union all
select '' as id,'d' as name from dual
union all
select '' as id,'' as name from dual
)
select distinct id,name name from t ;
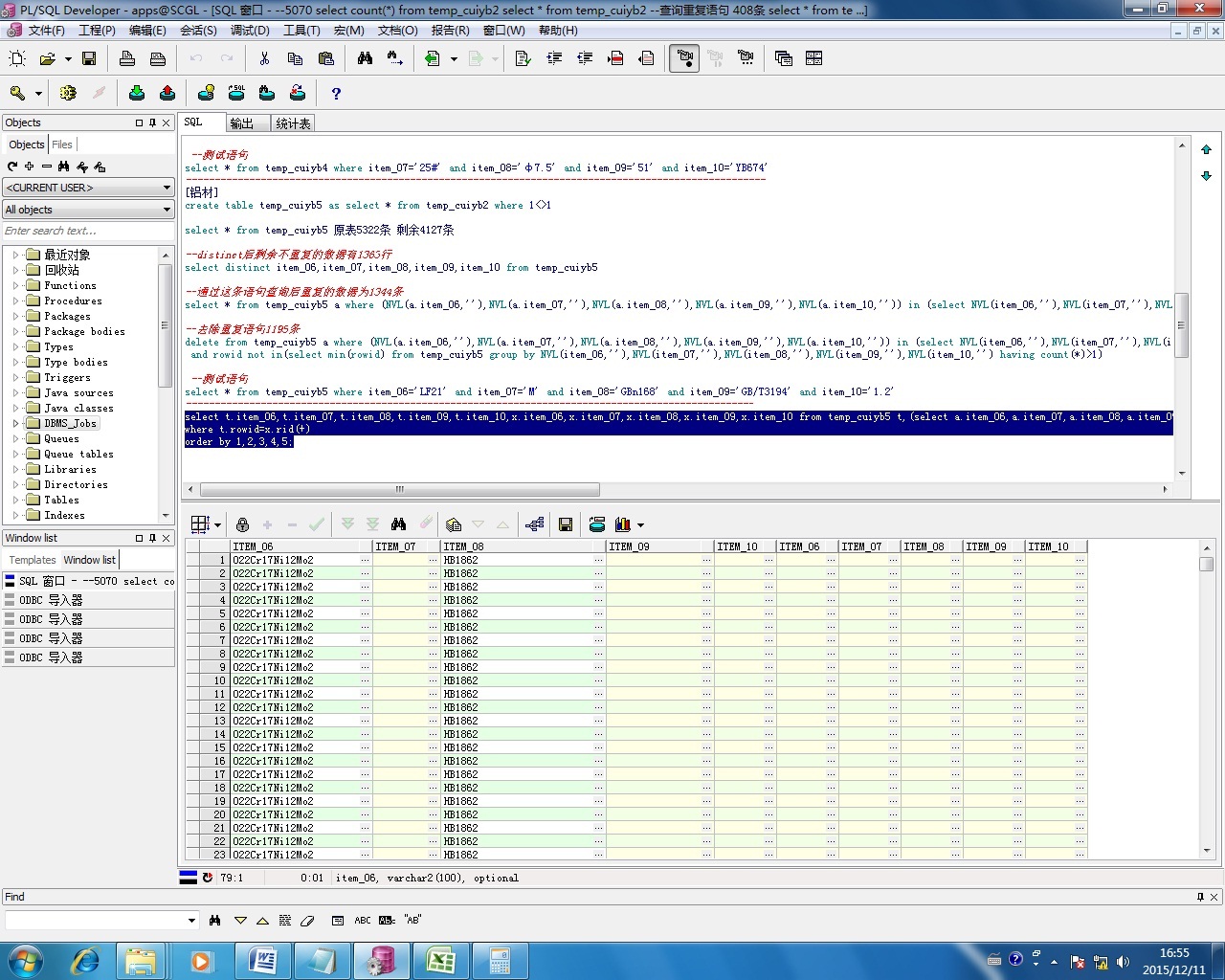
select distinct item_06,item_07,item_08,item_09,item_10 from temp --这里distinct后不包括item_06,item_07,item_08,item_09,item_10都为null的数据哦,你的数据会不会存在这四列都为null的数据呢,所以造成跟select * from temp 5322条数据差距,同样,group by 中也不会包括这四列都为空的数据