

37,738
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


>>>
2015-12-25 10:32:22.407000 飞机 38766
2015-12-25 10:32:22.879000 火车
import datetime
import time
import urllib
while True:
for a in ['飞机', '火车', '汽车', '轮船']:
url = r'http://ss.gkstk.com/cse/search?q='+a+r'&click=1&s=11259993741189624235'
req = urllib.urlopen(url)
print datetime.datetime.now(), a, len(req.read())
req.close()
2015-12-25 10:16:22.498518 飞机 38770
2015-12-25 10:16:22.754490 火车 39765
2015-12-25 10:16:23.016036 汽车 39371
2015-12-25 10:16:23.260760 轮船 38874
2015-12-25 10:16:23.498307 飞机 38770
2015-12-25 10:16:23.765754 火车 39765
2015-12-25 10:16:24.050302 汽车 39371
2015-12-25 10:16:24.328333 轮船 38874
2015-12-25 10:16:24.583839 飞机 38770
2015-12-25 10:16:24.882681 火车 39765
2015-12-25 10:16:25.180508 汽车 39371
2015-12-25 10:16:25.496497 轮船 38874
2015-12-25 10:16:25.771734 飞机 38770
2015-12-25 10:16:26.001684 火车 39765
2015-12-25 10:16:26.235687 汽车 39371
2015-12-25 10:16:26.469926 轮船 38874
2015-12-25 10:16:26.754045 飞机 38770
2015-12-25 10:16:27.160544 火车 39765
2015-12-25 10:16:27.399948 汽车 39371
2015-12-25 10:16:27.656756 轮船 38874
2015-12-25 10:16:27.897737 飞机 38770
2015-12-25 10:16:28.163222 火车 39765
2015-12-25 10:16:28.445390 汽车 39371
2015-12-25 10:16:28.676750 轮船 38874
2015-12-25 10:16:28.914525 飞机 38770
2015-12-25 10:16:29.180840 火车 39765
2015-12-25 10:16:29.420131 汽车 39371
2015-12-25 10:16:29.726095 轮船 38874
2015-12-25 10:16:29.967524 飞机 38770
2015-12-25 10:16:30.205105 火车 39765
2015-12-25 10:16:30.507945 汽车 39371
2015-12-25 10:16:30.822356 轮船 38874
2015-12-25 10:16:31.114813 飞机 38770
2015-12-25 10:16:31.423173 火车 39765
2015-12-25 10:16:31.713391 汽车 39371
2015-12-25 10:16:32.008701 轮船 38874
2015-12-25 10:16:32.275053 飞机 38770
2015-12-25 10:16:32.521600 火车 39765
2015-12-25 10:16:32.798019 汽车 39371
2015-12-25 10:16:33.099540 轮船 38874
2015-12-25 10:16:33.362301 飞机 38770
2015-12-25 10:16:33.610782 火车 39765
2015-12-25 10:16:33.904479 汽车 39371
2015-12-25 10:16:34.184339 轮船 38874
2015-12-25 10:16:34.422873 飞机 38770
2015-12-25 10:16:34.714822 火车 39765
2015-12-25 10:16:34.986098 汽车 39371
2015-12-25 10:16:35.228974 轮船 38874
2015-12-25 10:16:35.480587 飞机 38770
2015-12-25 10:16:35.720192 火车 39765
2015-12-25 10:16:36.017358 汽车 39371
2015-12-25 10:16:36.314360 轮船 38874
2015-12-25 10:16:36.553009 飞机 38770
2015-12-25 10:16:36.800480 火车 39765
a=raw_input(' 搜索:')
print '\n'
url=r'http://ss.gkstk.com/cse/search?q='+a+r'&click=1&s=11259993741189624235'
req = urllib2.urlopen(url)while True:
a=raw_input(' 搜索:')
print '\n'
url=r'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
content = urllib.urlopen(url).read()
list = re.findall(r"margin:0px 0;'>\s+(.*?)</div>",content)
for i in range(len(list)):
list[i]=list[i].replace(r'</em>',"").replace(r'<em>',"").replace(r'...',"")
print list[i],'\n'
print ' ==================================结束==================================\n're.search(r"margin:0px 0;'>\s+(.*?)</div>",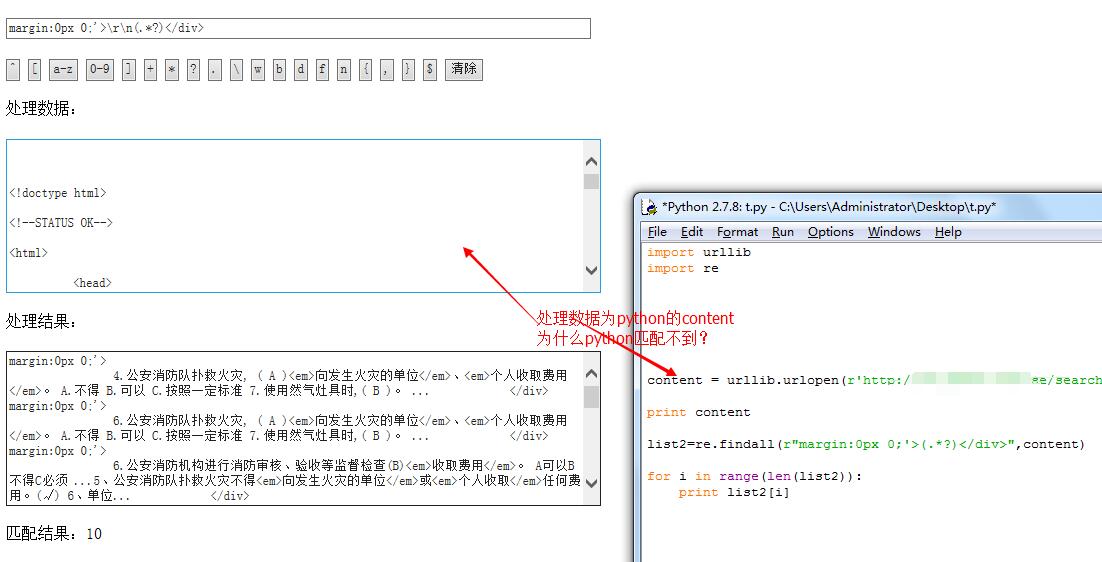
<div>
<div class="c-content">
<div class="c-abstract" style='font-family:Arial,SimSun,sans-serif;font-size:13px;color:#000000;
margin:0px 0;'>
6.公安消防队扑救火灾, ( A )<em>向发生火灾的单位</em>、<em>个人收取费用</em>。 A.不得 B.可以 C.按照一定标准 7.使用然气灶具时,( B )。 ... </div><div>
<div class="c-content">
<div class="c-abstract" style='font-family:Arial,SimSun,sans-serif;font-size:13px;color:#000000;
margin:0px 0;'>
6.公安消防队扑救火灾, ( A )<em>向发生火灾的单位</em>、<em>个人收取费用</em>。 A.不得 B.可以 C.按照一定标准 7.使用然气灶具时,( B )。 ... </div>content = req.read()
req.close()
print "AAAA"
req = urllib.urlopen(url)
print "BBBB"
content = req.read()
print "CCCC"


